Celebrado los días: 20, 23, 27 y 30 de mayo de 2024
Copyright y derechos:
Curso estadística 2024 para el Servei de Formació Permanent by Adrián Cabedo Nebot is licensed under CC BY 4.0
1 Programa del curso
1.1 Resumen
El curso ofrece una inmersión completa en el análisis y aprovechamiento de bases de datos lingüísticas, superando las limitaciones de herramientas convencionales como Excel y Google Sheets. Los participantes adquirirán una sólida comprensión de R, un lenguaje de programación esencial en análisis de datos. Además, explorarán técnicas estadísticas avanzadas para visualizar y analizar datos lingüísticos y poblacionales. Aprenderán a crear visualizaciones descriptivas impactantes utilizando GGplot2, aplicarán Mosaicplot y pruebas de chi cuadrado para investigar relaciones categóricas, identificarán patrones en datos multidimensionales mediante análisis de correspondencias y componentes, utilizarán árboles de decisiones para tomar decisiones basadas en datos y explorarán relaciones no lineales, y generarán mapas de calor para visualizar correlaciones y tendencias en datos numéricos. Este curso proporciona una base para el análisis avanzado de datos lingüísticos y poblacionales.
1.2 Objetivos específicos
• Adquirir habilidades avanzadas en el manejo de bases de datos lingüísticas más allá de las hojas de cálculo tradicionales como Excel o Google Sheets.
• Familiarizarse con el programa R, aprendiendo los conceptos básicos de programación y análisis de datos en este entorno.
• Desarrollar la capacidad de representar datos de manera efectiva utilizando técnicas de visualización avanzadas, incluyendo barras, lolipops, diagramas de caja y líneas temporales utilizando GGplot2 en R.
• Adquirir habilidades avanzadas en el análisis de datos, utilizando diversas técnicas estadísticas y de visualización, como Mosaicplot y pruebas de chi cuadrado para explorar relaciones entre variables categóricas, análisis de correspondencias múltiples y análisis de componentes para identificar patrones en datos multidimensionales, la construcción de árboles de decisiones para tomar decisiones basadas en datos y la exploración de relaciones no lineales, así como la generación de mapas de calor para visualizar patrones de correlación y tendencias en datos numéricos.
1.3 Contenidos
Análisis y explotación de una base de datos lingüística: más allá de Excel/Goole Sheets
Introducción básica al manejo del programa R
Técnicas estadísticas de visualización y contraste poblacional
Visualización descriptiva (barras, lolipops, diagramas de caja, líneas temporales…) con GGplot2.
Mosaicplot y chi cuadrado Análisis múltiple de correspondencias / Análisis de componentes
Árboles de decisiones
Mapas de calor
1.4 Conocimientos previos
Se recomienda a las personas interesadas en realizar el curso que tengan un conocimiento básico de programas de hojas de datos como, por ejemplo, Excel o, al menos, que conozcan su estructura general. También es recomendable que hayan realizado investigaciones previas con datos.
1.5 Requisitos técnicos
Se recomienda a quien acuda al curso que tenga previamente instalado R (https://cran.rediris.es/) y RStudio (https://posit.co/download/rstudio-desktop) en su propio ordenador portátil, independientemente de que la realización del curso pueda impartirse en algún aula con ordenadores. Ambos son programas gratuitos y pueden instalarse en Linux, Windows y Mac.
1.6 Sobre los datos de este curso
En este curso, utilizaremos datos lingüísticos, específicamente datos pragmáticos y fónicos, como ejemplos prácticos para aprender a trabajar con R y desarrollar habilidades estadísticas avanzadas. Sin embargo, es importante comprender que el enfoque principal de este curso va más allá de los datos lingüísticos en sí. Las técnicas y pruebas que aprenderán aquí son universales y se pueden aplicar a una amplia gama de datos en diferentes campos y disciplinas. Nuestro objetivo es capacitar a quienes asistan para que se conviertan en analistas de datos competentes y versátiles que puedan abordar y resolver problemas utilizando R y técnicas estadísticas, independientemente del tipo de datos con el que trabajen en el futuro.
1.7 Evaluación
Los contenidos se evaluarán a través de la asistencia y las prácticas realizadas en el aula, así como de la realización de un breve cuestionario online a la finalización del curso. En este cuestionario se preguntará sobre los ejemplos prácticos expuestos en clase.
1.8 Bibliografía recomendada
Referencias recomendas
Este mismo documento.
Cabedo Nebot, A. (2021). Fundamentos de estadística con R para lingüistas. Tirant Lo Blanch.
Levshina, N. (2015). How to do Linguistics with R: Data exploration and statistical analysis. John Benjamins Publishing Company.
Moore, D. S., & McCabe, G. P. (1999). Introduction to the practice of statistics. W.H. Freeman.
Navarro, D. (2015). Learning statistics with R: A tutorial for psychology students and other beginners. (. University of Adelaide. https://learningstatisticswithr.com/
Análisis Estadístico: Desde análisis descriptivos básicos hasta modelos estadísticos avanzados y pruebas de hipótesis.
Visualización de Datos: Creación de gráficos y mapas detallados para explorar y presentar datos de manera efectiva.
Manipulación de Datos: Transformación, limpieza y preparación de datos para análisis mediante paquetes como dplyr y tidyr.
Modelado Predictivo: Desarrollo de modelos de machine learning, incluyendo regresión, clasificación y clustering.
Generación de Informes: Automatización de informes y creación de documentos reproducibles con R Markdown.
Interfaz de Programación: Desarrollo de aplicaciones interactivas y dashboards usando Shiny para presentaciones dinámicas de datos.
4 Sobre R (II)
Vale, pero, ¿qué hace realmente R?
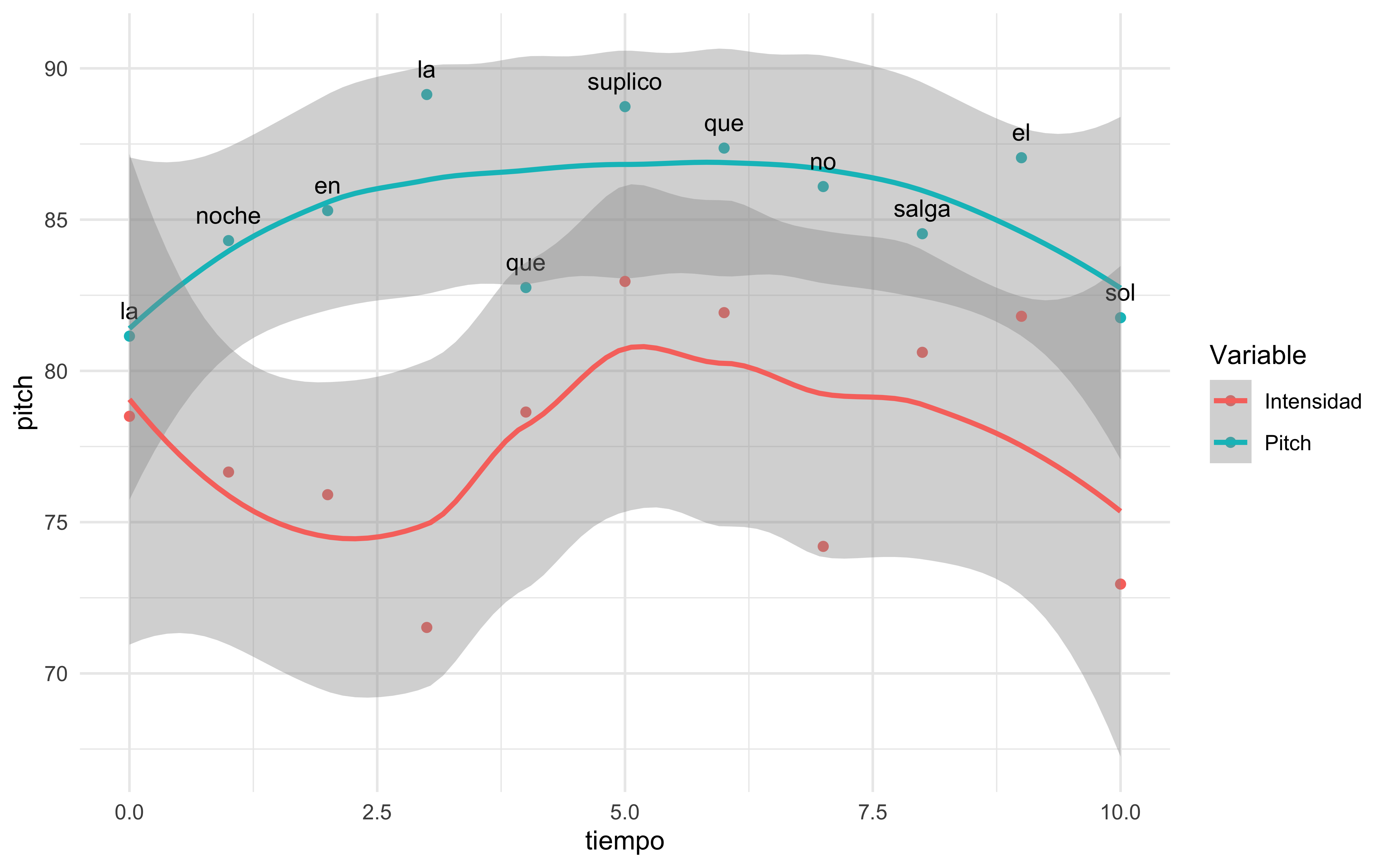
library(tidyverse)library(gridExtra)frase <-unlist(strsplit("la noche en la que suplico que no salga el sol", " "))# Crear el data framedatos <-data.frame(palabra = frase, tiempo =seq(0, length(frase) -1), pitch =runif(length(frase), min=80, max=90), intensidad =runif(length(frase), min=70, max=85) )# Create the plot with labelsplot <-ggplot(datos) +geom_point(aes(x = tiempo, y = pitch, color ="Pitch")) +geom_smooth(aes(x = tiempo, y = pitch, color ="Pitch")) +geom_text(aes(x = tiempo, y = pitch, label = palabra), vjust =-1, hjust =0.5, size =3.5, check_overlap =TRUE) +geom_point(aes(x = tiempo, y = intensidad, color ="Intensidad")) +geom_smooth(aes(x = tiempo, y = intensidad, color ="Intensidad")) +labs(color ="Variable") +# Add text labels above pointstheme_minimal() plot
Figura extraída con GGplot2. Curva melódica y de intensidad del enunciado la noche en la que no salga el sol
5 ¿Qué más puedo hacer con R?
Más funcionalidades
Escribir documentos científicos mediante Rmarkdown o Quarto (este mismo documento ha sido escrito en R).
Exportar tus documentos a varios formatos: PDF, Word o Powerpoint.
Modificación de las plantillas. Ejemplo: revista Normas de la UV.
Programar scripts que realicen funciones de manera automática. Por ejemplo, abre todos los archivos de una carpeta e impórtalos.
Crear aplicaciones web para consultar datos. Ej.: Oralstats.
Explora la base de datos Idiolectal en Excel o Google Sheets.
8.5 Definir la construcción de la base de datos (estructura)
flowchart LR A[Investigación] --> B(Base de datos) B --> C{Variables} C --> D[elemento de análisis] C --> E[F0 media] C --> F[Intensidad media] C --> G[Cortesía] C --> H[...]
flowchart LR
A[Investigación] --> B(Base de datos)
B --> C{Variables}
C --> D[elemento de análisis]
C --> E[F0 media]
C --> F[Intensidad media]
C --> G[Cortesía]
C --> H[...]
Figura. Proceso de construcción de la base de datos.
9.4 Conoce la estructura de tus datos: str o summary
str(fonocortesia)
tibble [282 × 36] (S3: tbl_df/tbl/data.frame)
$ Conversacion : chr [1:282] "VALESCO 114A" "VALESCO 130A" "VALESCO 194A" "VALESCO 114A" ...
$ Cortes_Descortes : chr [1:282] "descortés" "descortés" "descortés" "descortés" ...
$ Llama_Atencion : chr [1:282] "acento;entonación;velocidad de habla" "acento;duración;entonación" "acento;duración;velocidad de habla" "acento;entonación;velocidad de habla" ...
$ Mediodeexpresion : chr [1:282] "Fórmulas indirectas" "Atenuación" "Intensificación" "Intensificación" ...
$ F0_Inicial : num [1:282] 227 213 242 148 249 ...
$ F0_Final : num [1:282] 292 226 422 125 224 ...
$ F0_Media : num [1:282] 298 174 315 224 226 ...
$ F0_Maxima : num [1:282] 441 301 498 121 334 ...
$ F0_Minima : num [1:282] 225 70.2 108 461 111.7 ...
$ Intensidad_Maxima : num [1:282] 89 86 86 89 87 86 90 89 NA 64 ...
$ Intensidad_Minima : num [1:282] 71 74 59 68 83 61 66 69 NA 45 ...
$ Intensidad_Primera : num [1:282] 84 77 83 77 80 80 85 70 NA NA ...
$ Intensidad_Ultima : num [1:282] 85 80 70 76 83 80 88 81 NA NA ...
$ Intensidad_Media : num [1:282] 85 78 81 85 83 80 85 84 0 57 ...
$ Silabas : num [1:282] 4.1 19 41 37 39 38 31 39 47 0 ...
$ Duracion : num [1:282] 33 9 7.6 7.4 7.2 6.9 6 6 6 5.62 ...
$ Duracion_Pausa_Anterior : num [1:282] 0 1 0 0 0 0.6 0 0 0 0 ...
$ Duracion_Pausa_Posterior : num [1:282] 0 2.1 0 0 0.5 0 0 0 0 0 ...
$ Continuacion_Pausa : chr [1:282] "continúa otro hablante" "continúa otro hablante" "continúa otro hablante" "continúa el mismo hablante" ...
$ Curva_Melodica : chr [1:282] "suspensión" "suspensión" "circunfleja" "inclinación" ...
$ Otro_Curva_Melodica : chr [1:282] "desconocido" "desconocido" "desconocido" "desconocido" ...
$ Inflexion_Local_Interna : chr [1:282] "ascendente" "ninguna" "ascendente_descendente" "ascendente" ...
$ Tonema : chr [1:282] "suspendido" "suspendido" "ascendente" "descendente" ...
$ Unidad_Del_Discurso : chr [1:282] "Intervención reactiva" "acto;Intervención iniciativo-reactiva" "acto;Intervención reactiva;turno" "Intervención reactivo-iniciativa;turno" ...
$ Valormodal : chr [1:282] "aserción" "desconocido" "negación" "aserción" ...
$ Otro_Valor_Modal : chr [1:282] "desconocido" "Amenaza" "Respuesta" "desconocido" ...
$ Fenomeno_Tonal : chr [1:282] "entonación suspendida" "entonación suspendida" "ascenso brusco de la curva melódica" "ascenso brusco de la curva melódica" ...
$ Fenomeno_Duracion : chr [1:282] "alargamiento" "alargamiento" "ninguno" "ninguno" ...
$ Fenomeno_Pausas : chr [1:282] "desconocido" "pausas largas" "pausas cortas" "pocas pausas" ...
$ Fenomeno_Velocidad : chr [1:282] "velocidad de habla rápida" "velocidad de habla lenta" "velocidad de habla rápida" "ninguno" ...
$ Fenomeno_Amplitud : chr [1:282] "campo tonal alto" "ninguno" "campo tonal alto" "ninguno" ...
$ Unidad_Fonica : chr [1:282] "cláusula entonativa" "grupo entonativo" "cláusula entonativa" "paratono" ...
$ Estrategia_Pragmatica : chr [1:282] "recriminación" "desconocido" "Ofrecer información" "recriminación;desacuerdo" ...
$ Efecto_Pragmatico_Asociado: chr [1:282] "desconocido" "desconocido" "Ninguno" "desconocido" ...
$ Elemento_Analizado : chr [1:282] "si me lo ha dicho a mí ella" "M: (...) si no tee- no te sacas un futuro↑/// asín quee↓// aprieta porque sino→" "M: porque NOO/ porque me pongo a discutir↑ otra vez con ella / y con ella↑ es inútil discutir↓ hay que [darle la=]" "y si desde que tú vas diciéndome/ na(da) na na na\r\n" ...
$ Fragmento : chr [1:282] "C: si me lo ha dicho a mí ella↓ ella allí tiene el historial del PAPA↓ allí en la ofici– y tiene también el [hi"| __truncated__ "M: estudiar // tú porque no quieres estudiar // pero imagínate que tú no-tú no // si no tee- no te sacas un fut"| __truncated__ "P: a A si que la quieres→/ o si no↑ cuenta lo que ha pasado hoy con la conducción§\r\nM: § no\r\nP: ¿por QUÉ?\r"| __truncated__ "A: y si desde que tú vas diciéndome/ na(da) na na na↑ ya son trenta billetes que hubiera perdido↓ TRENTA/// ¿¡"| __truncated__ ...
summary(fonocortesia)
Conversacion Cortes_Descortes Llama_Atencion Mediodeexpresion
Length:282 Length:282 Length:282 Length:282
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
F0_Inicial F0_Final F0_Media F0_Maxima
Min. : 0.0 Min. : 0.0 Min. : 0.0 Min. : 0.0
1st Qu.:161.8 1st Qu.:145.9 1st Qu.:180.0 1st Qu.:228.2
Median :219.7 Median :210.1 Median :221.4 Median :286.0
Mean :212.7 Mean :210.0 Mean :215.3 Mean :287.6
3rd Qu.:252.2 3rd Qu.:266.3 3rd Qu.:251.7 3rd Qu.:356.0
Max. :490.0 Max. :519.0 Max. :419.6 Max. :528.0
NA's :42 NA's :42
F0_Minima Intensidad_Maxima Intensidad_Minima Intensidad_Primera
Min. : 0.0 Min. :52.00 Min. : 40.00 Min. :51.00
1st Qu.:100.7 1st Qu.:73.75 1st Qu.: 55.00 1st Qu.:75.00
Median :133.6 Median :86.00 Median : 72.00 Median :81.00
Mean :142.6 Mean :80.62 Mean : 67.32 Mean :79.18
3rd Qu.:185.8 3rd Qu.:89.00 3rd Qu.: 77.00 3rd Qu.:86.00
Max. :461.0 Max. :90.00 Max. :107.00 Max. :90.00
NA's :2 NA's :2 NA's :49
Intensidad_Ultima Intensidad_Media Silabas Duracion
Min. :54.00 Min. : 0.00 Min. : 0.00 Min. : 0.000
1st Qu.:72.00 1st Qu.: 66.00 1st Qu.: 6.00 1st Qu.: 1.000
Median :77.00 Median : 81.00 Median : 9.50 Median : 1.500
Mean :76.59 Mean : 76.76 Mean :11.54 Mean : 2.042
3rd Qu.:84.00 3rd Qu.: 86.00 3rd Qu.:15.00 3rd Qu.: 2.400
Max. :89.00 Max. :222.00 Max. :47.00 Max. :33.000
NA's :49
Duracion_Pausa_Anterior Duracion_Pausa_Posterior Continuacion_Pausa
Min. : 0.0000 Min. : 0.0000 Length:282
1st Qu.: 0.0000 1st Qu.: 0.0000 Class :character
Median : 0.0000 Median : 0.0000 Mode :character
Mean : 0.3939 Mean : 0.5122
3rd Qu.: 0.5000 3rd Qu.: 0.6000
Max. :15.0000 Max. :36.0000
Curva_Melodica Otro_Curva_Melodica Inflexion_Local_Interna
Length:282 Length:282 Length:282
Class :character Class :character Class :character
Mode :character Mode :character Mode :character
Tonema Unidad_Del_Discurso Valormodal Otro_Valor_Modal
Length:282 Length:282 Length:282 Length:282
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
Fenomeno_Tonal Fenomeno_Duracion Fenomeno_Pausas Fenomeno_Velocidad
Length:282 Length:282 Length:282 Length:282
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
Fenomeno_Amplitud Unidad_Fonica Estrategia_Pragmatica
Length:282 Length:282 Length:282
Class :character Class :character Class :character
Mode :character Mode :character Mode :character
Efecto_Pragmatico_Asociado Elemento_Analizado Fragmento
Length:282 Length:282 Length:282
Class :character Class :character Class :character
Mode :character Mode :character Mode :character
9.5 Citar R
citation()
To cite R in publications use:
R Core Team (2024). _R: A Language and Environment for Statistical
Computing_. R Foundation for Statistical Computing, Vienna, Austria.
<https://www.R-project.org/>.
A BibTeX entry for LaTeX users is
@Manual{,
title = {R: A Language and Environment for Statistical Computing},
author = {{R Core Team}},
organization = {R Foundation for Statistical Computing},
address = {Vienna, Austria},
year = {2024},
url = {https://www.R-project.org/},
}
We have invested a lot of time and effort in creating R, please cite it
when using it for data analysis. See also 'citation("pkgname")' for
citing R packages.
citation("tidyverse")
To cite package 'tidyverse' in publications use:
Wickham H, Averick M, Bryan J, Chang W, McGowan LD, François R,
Grolemund G, Hayes A, Henry L, Hester J, Kuhn M, Pedersen TL, Miller
E, Bache SM, Müller K, Ooms J, Robinson D, Seidel DP, Spinu V,
Takahashi K, Vaughan D, Wilke C, Woo K, Yutani H (2019). "Welcome to
the tidyverse." _Journal of Open Source Software_, *4*(43), 1686.
doi:10.21105/joss.01686 <https://doi.org/10.21105/joss.01686>.
A BibTeX entry for LaTeX users is
@Article{,
title = {Welcome to the {tidyverse}},
author = {Hadley Wickham and Mara Averick and Jennifer Bryan and Winston Chang and Lucy D'Agostino McGowan and Romain François and Garrett Grolemund and Alex Hayes and Lionel Henry and Jim Hester and Max Kuhn and Thomas Lin Pedersen and Evan Miller and Stephan Milton Bache and Kirill Müller and Jeroen Ooms and David Robinson and Dana Paige Seidel and Vitalie Spinu and Kohske Takahashi and Davis Vaughan and Claus Wilke and Kara Woo and Hiroaki Yutani},
year = {2019},
journal = {Journal of Open Source Software},
volume = {4},
number = {43},
pages = {1686},
doi = {10.21105/joss.01686},
}
9.6 Data frames
Un data frame es una estructura de datos en R que se utiliza para almacenar datos en forma tabular. Es similar a una matriz, pero cada columna puede contener un tipo de datos diferente.
Los data frames se pueden visualizar en RStudio en la pestaña “Environment” o escribiendo el nombre del data frame en la consola. Para mejorar la visualización, puedes usar la función View().
10 Tareas de limpieza y manipulación de datos
Revisión y corrección de valores faltantes:
Identificar y manejar los valores no disponicles (NA en R).
Decidir si imputar los valores faltantes con la media, mediana, moda, o algún otro método, o eliminar las filas/columnas con valores faltantes.
Detección y manejo de valores atípicos:
Identificar valores atípicos o outliers que pueden distorsionar el análisis.
Decidir si eliminar, transformar o tratar de otra manera estos valores.
Estandarización y normalización de datos:
Estandarizar unidades de medida para asegurarse de que sean consistentes.
Normalizar o estandarizar variables si es necesario para ciertos tipos de análisis.
Conversión de tipos de datos:
Asegurarse de que los datos estén en los tipos adecuados (por ejemplo, convertir variables categóricas a factores en R).
Revisión de la coherencia de los datos:
Verificar que no haya inconsistencias en los datos (por ejemplo, un valor de edad negativo).
Asegurar que los valores categóricos estén correctamente codificados y no haya variaciones como “Hombre” y “hombre”.
Eliminación de duplicados:
Identificar y eliminar registros duplicados que puedan afectar el análisis.
Corrección de errores tipográficos y de entrada de datos:
Revisar y corregir errores tipográficos o de entrada manual en los datos.
Creación de variables derivadas:
Crear nuevas variables que puedan ser útiles para el análisis, como agregar una variable que represente la diferencia entre dos fechas (edad, duración, etc.).
Filtrado de datos irrelevantes:
Eliminar columnas o filas que no sean relevantes para el análisis específico.
En esta sección, aprenderemos a visualizar datos utilizando el paquete ggplot2 en R. GGplot2 es una librería de visualización de datos en R que permite crear gráficos de alta calidad de manera sencilla y flexible.
11.1 ¿Por qué visualizar datos?
Visualizar datos es una parte fundamental del análisis de datos. Las visualizaciones permiten explorar los datos, identificar patrones y tendencias, comunicar resultados y conclusiones, y tomar decisiones adecuadas y coherentes. Las visualizaciones efectivas pueden ayudar a resumir y presentar datos de manera clara y concisa; esto facilita la interpretación y comprensión de los datos.
Images created by an AI from OpenAI
11.2 ¿Qué es ggplot2?
GGplot2 es una librería de visualización de datos en R que permite crear gráficos de alta calidad de manera sencilla y flexible. GGplot2 se basa en la gramática de gráficos, un enfoque que descompone los gráficos en componentes básicos (datos, estética, geometría, estadísticas y facetas) y permite construir gráficos complejos combinando estos componentes de manera intuitiva.
11.3 Tipos de gráficos
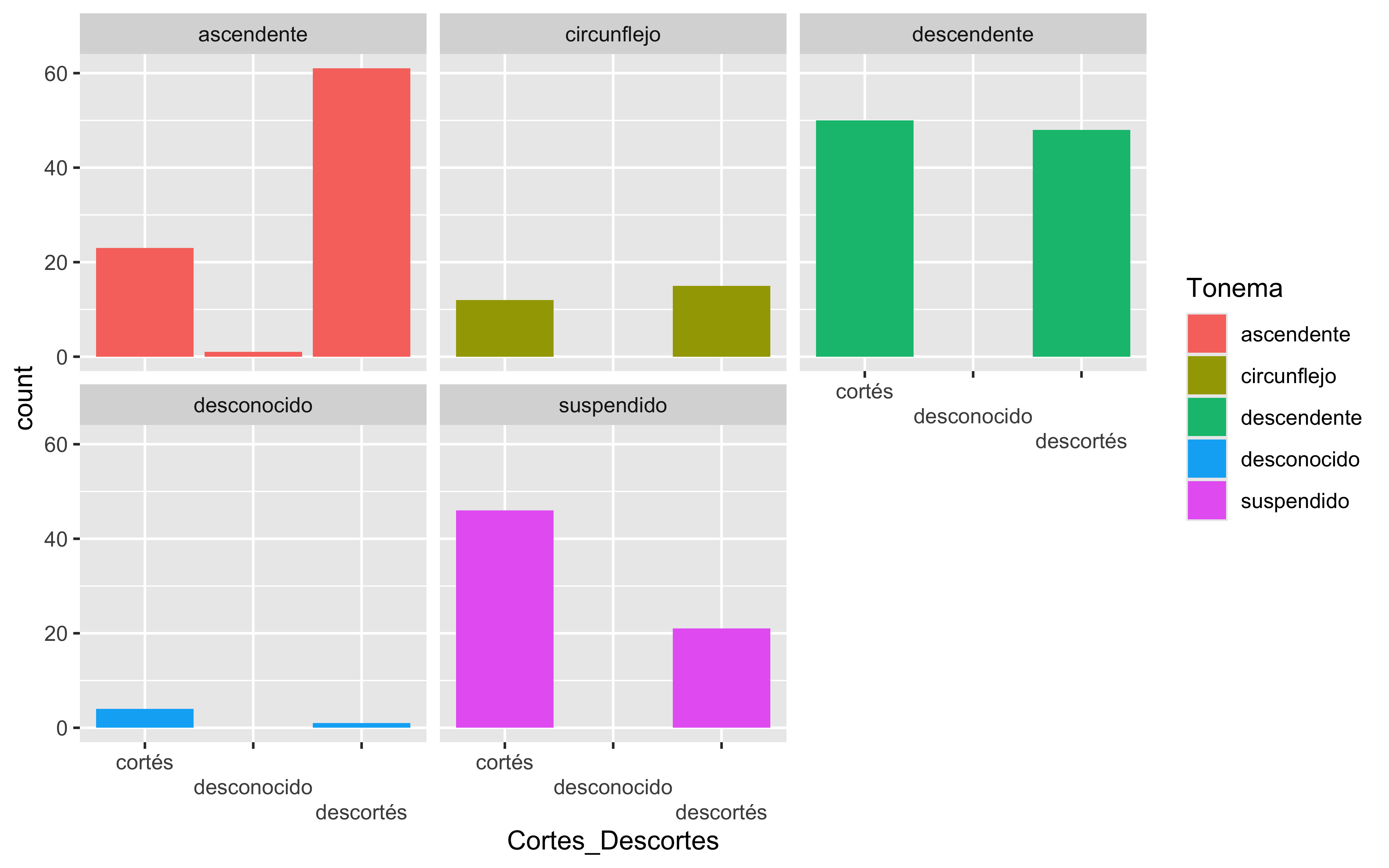
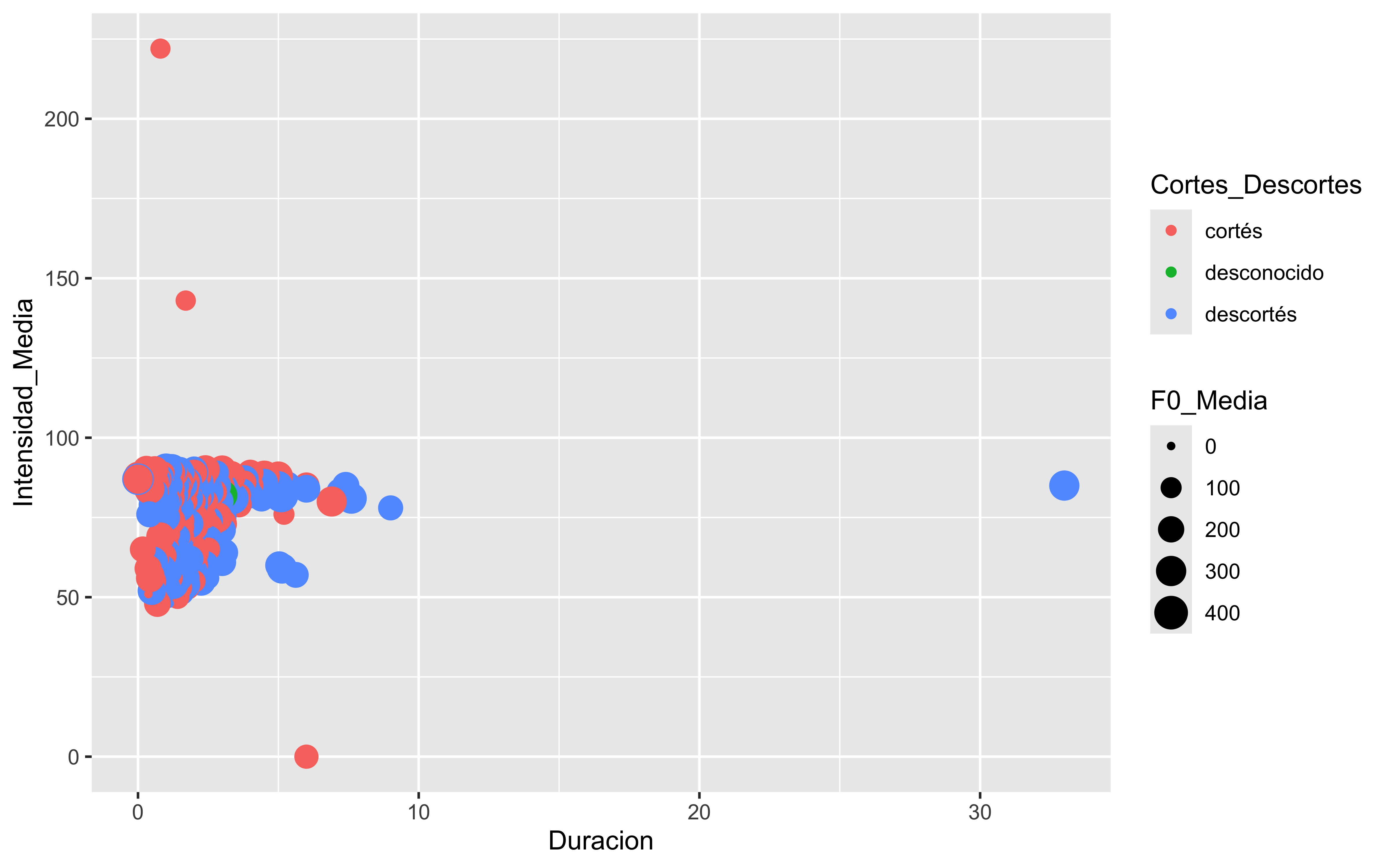
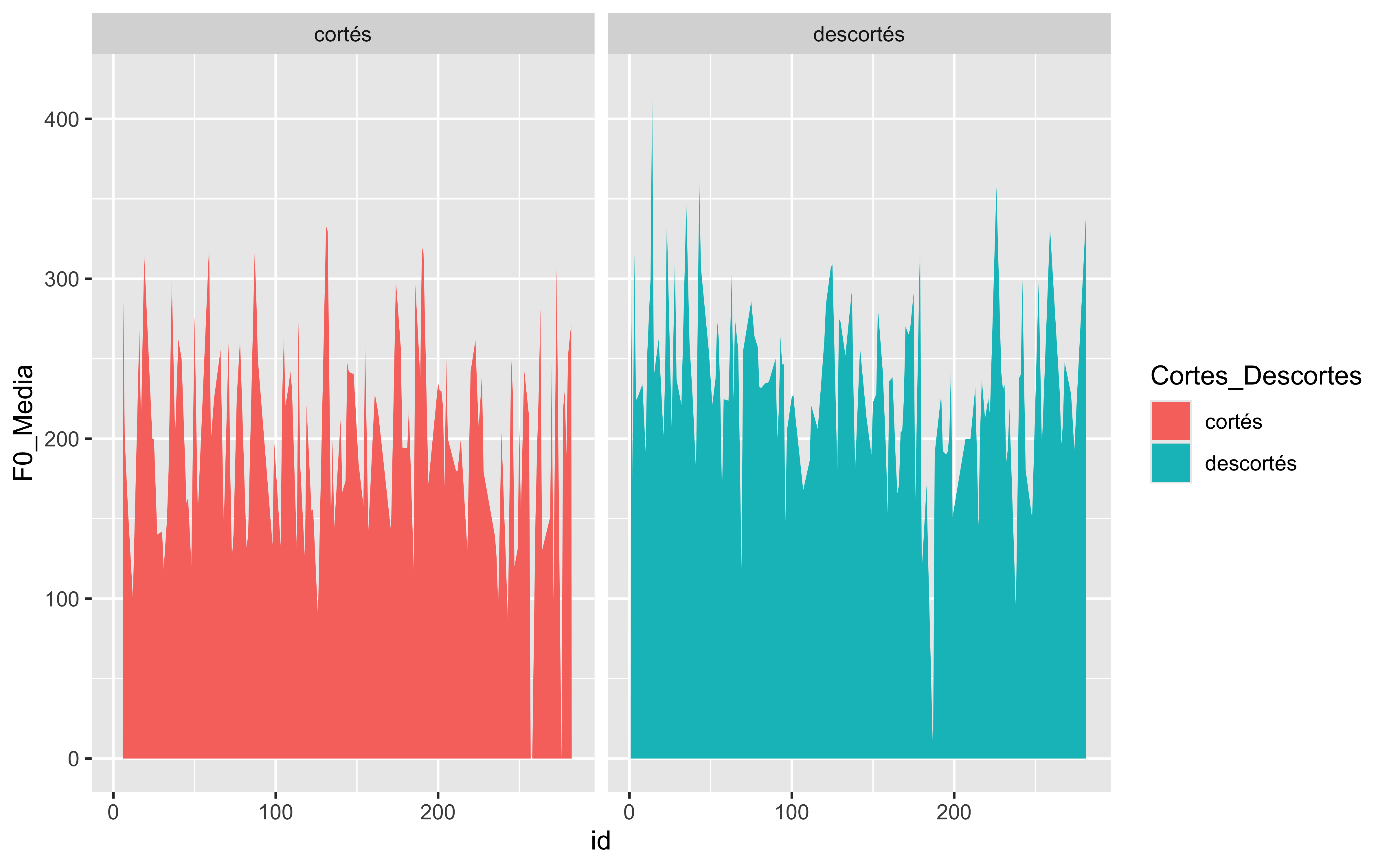
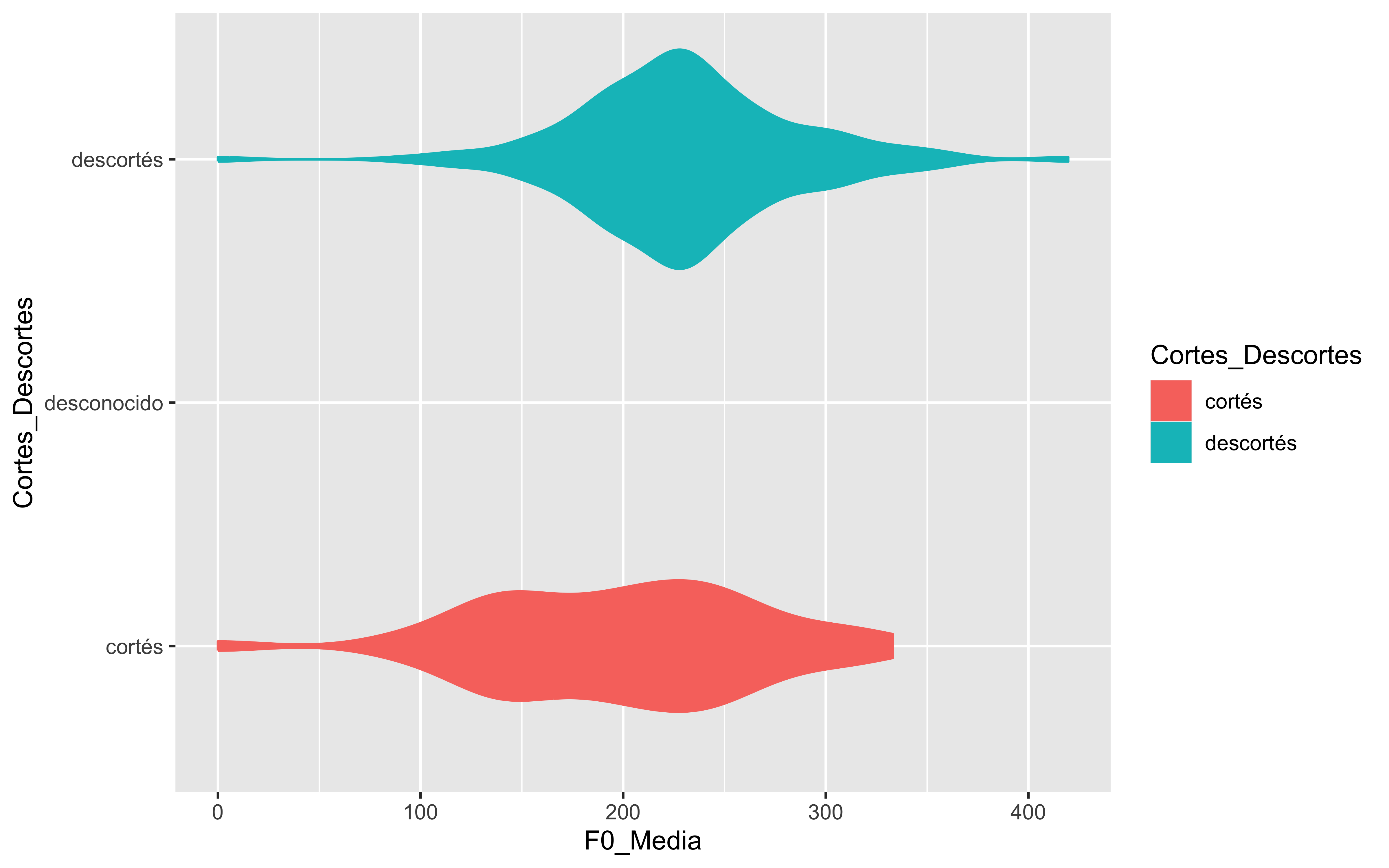
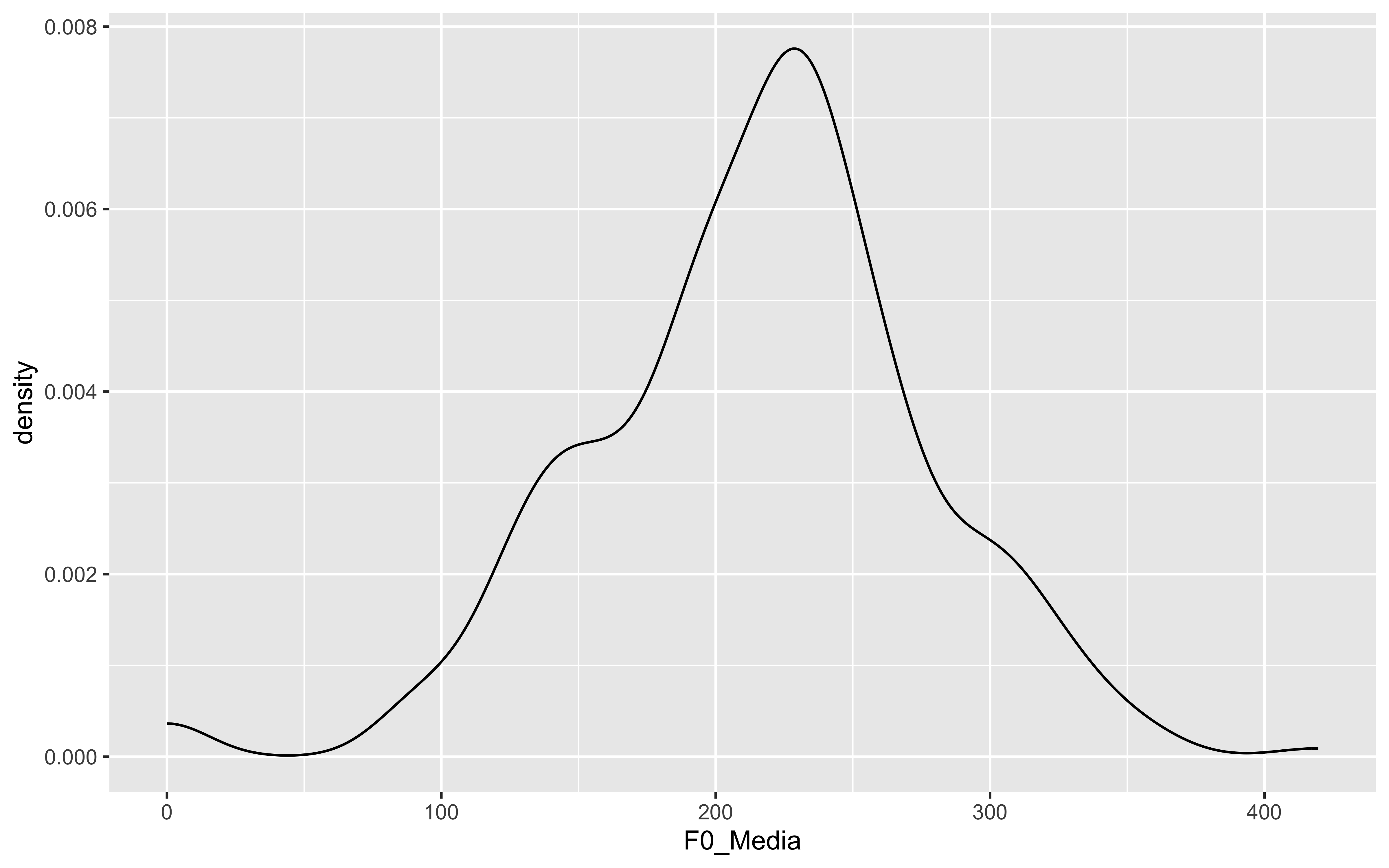
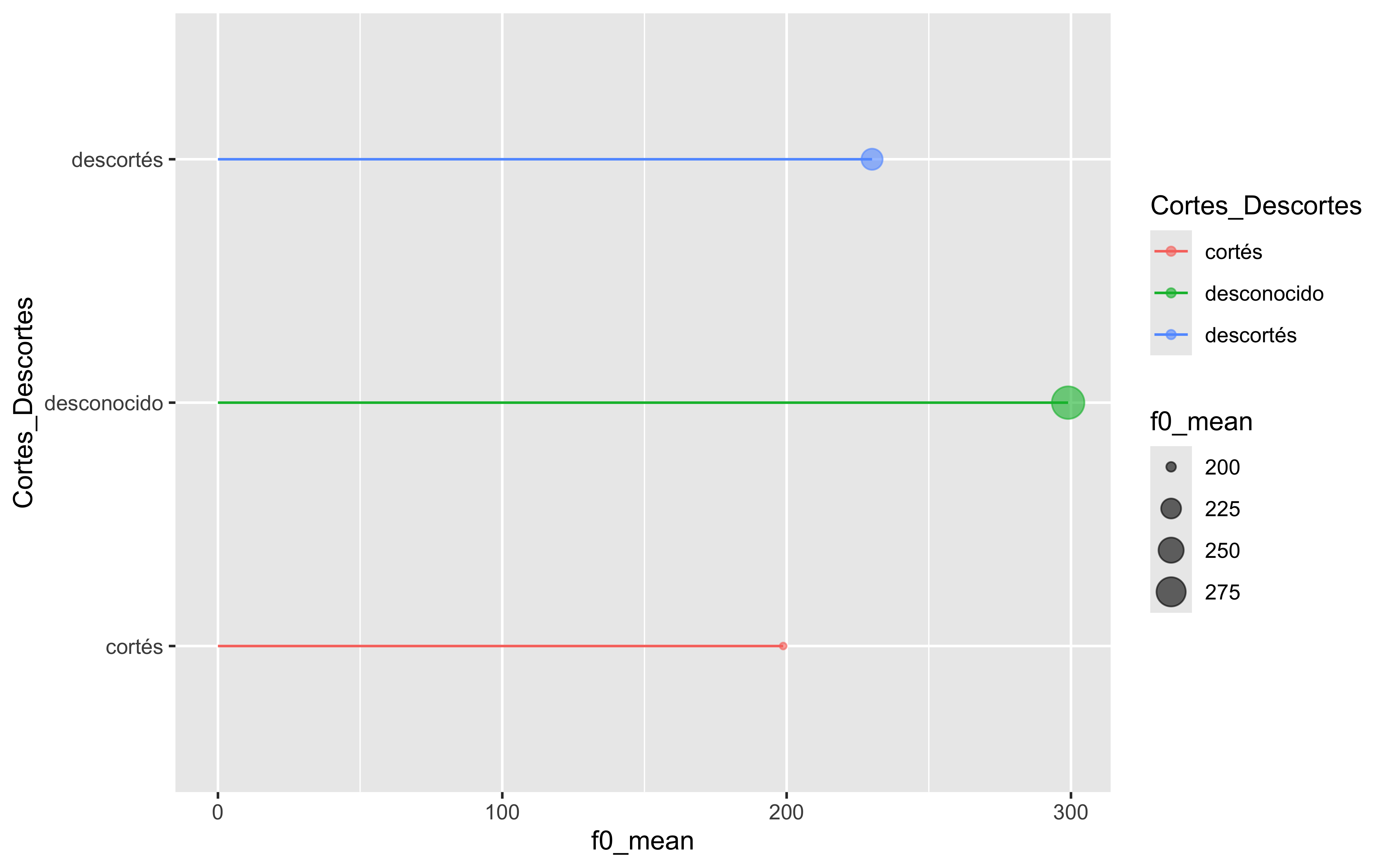
Los gráficos más comunes que se pueden crear con ggplot2 incluyen: gráfico de barras, gráfico de líneas, gráfico de dispersión, gráfico de violín, gráfico de áreas, gráfico de burbujas, gráfico de donut, gráfico de lolipop, gráfico de mapa de calor, gráfico de densidad, gráfico de correlaciones, gráfico de árbol…
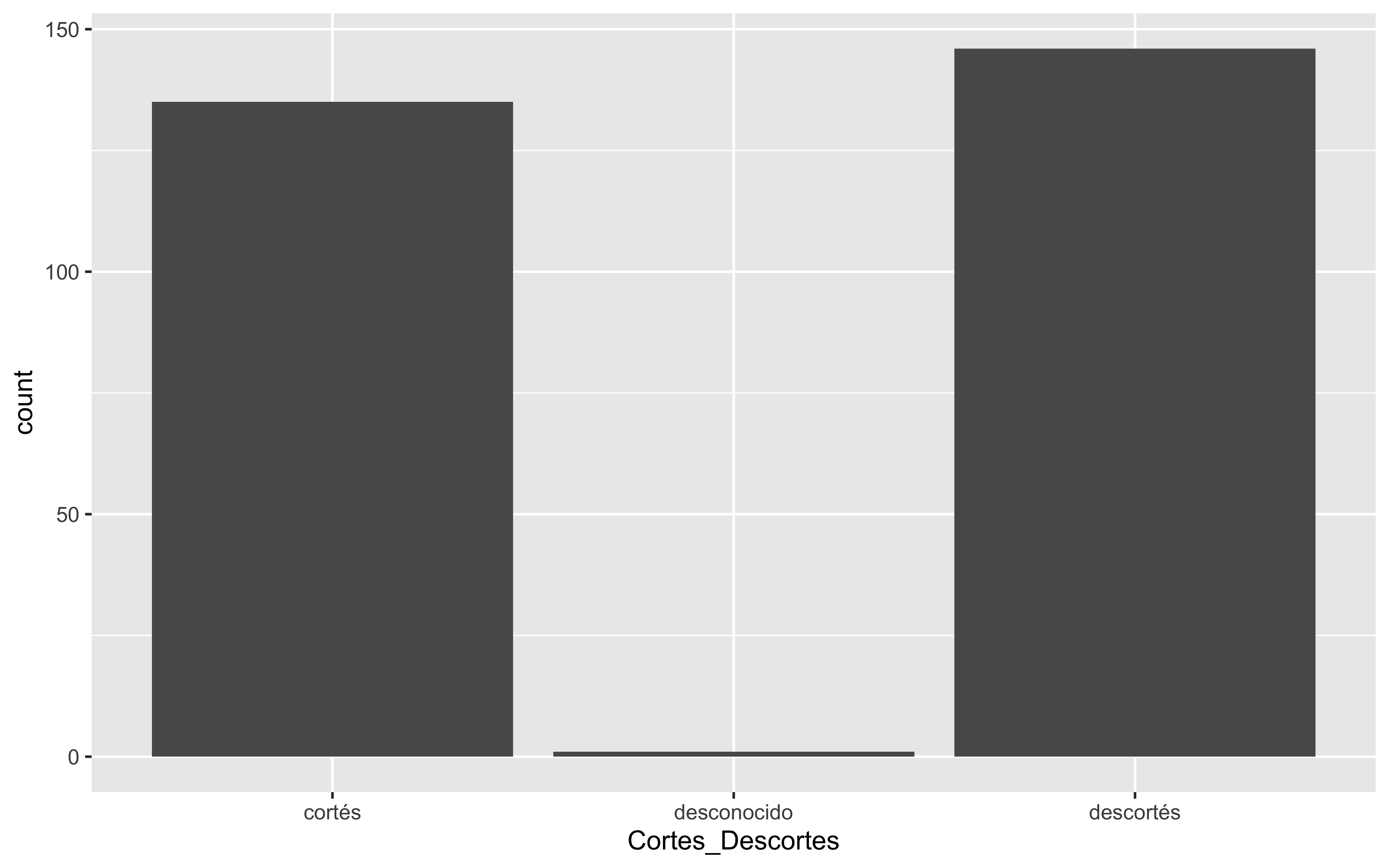
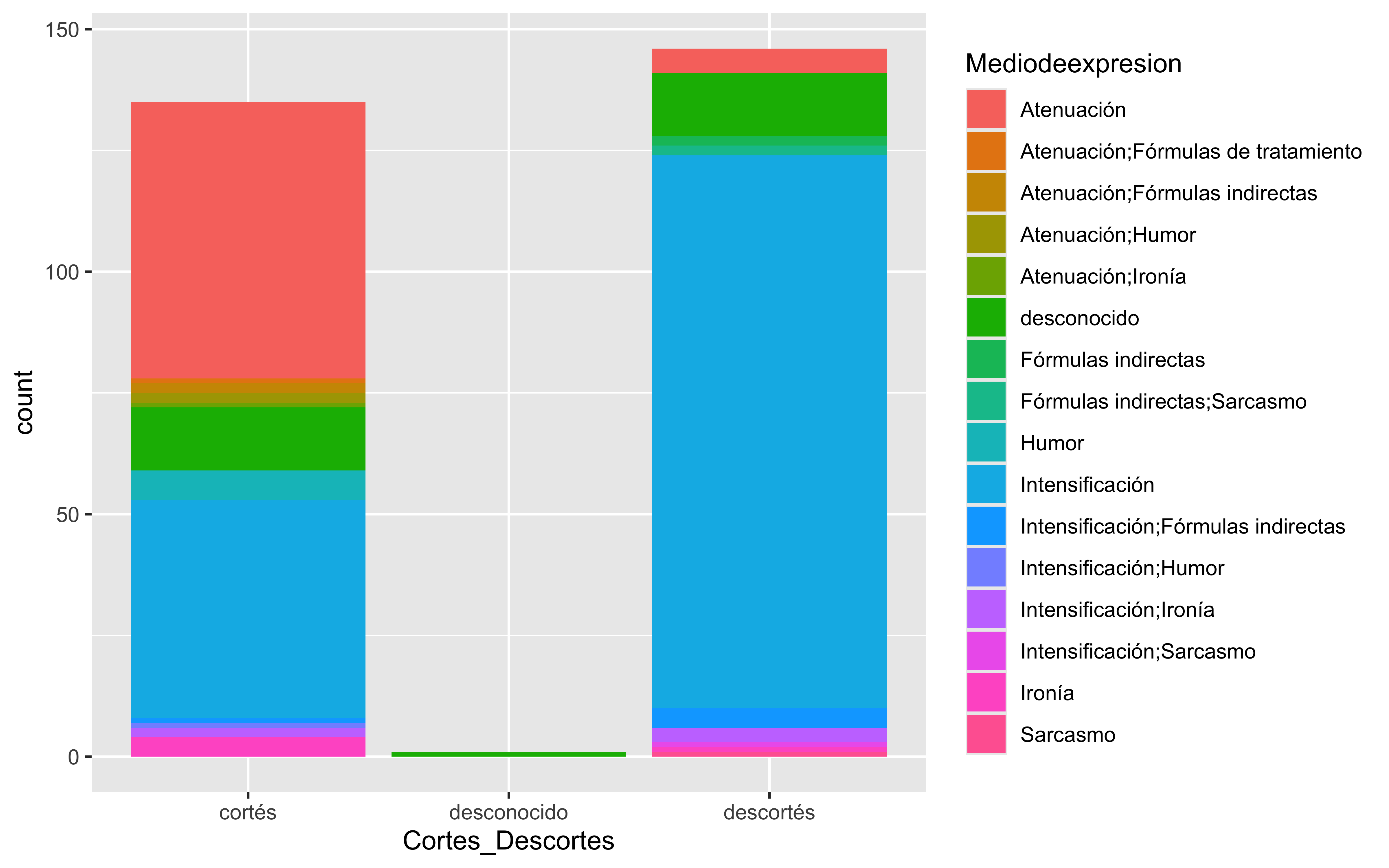
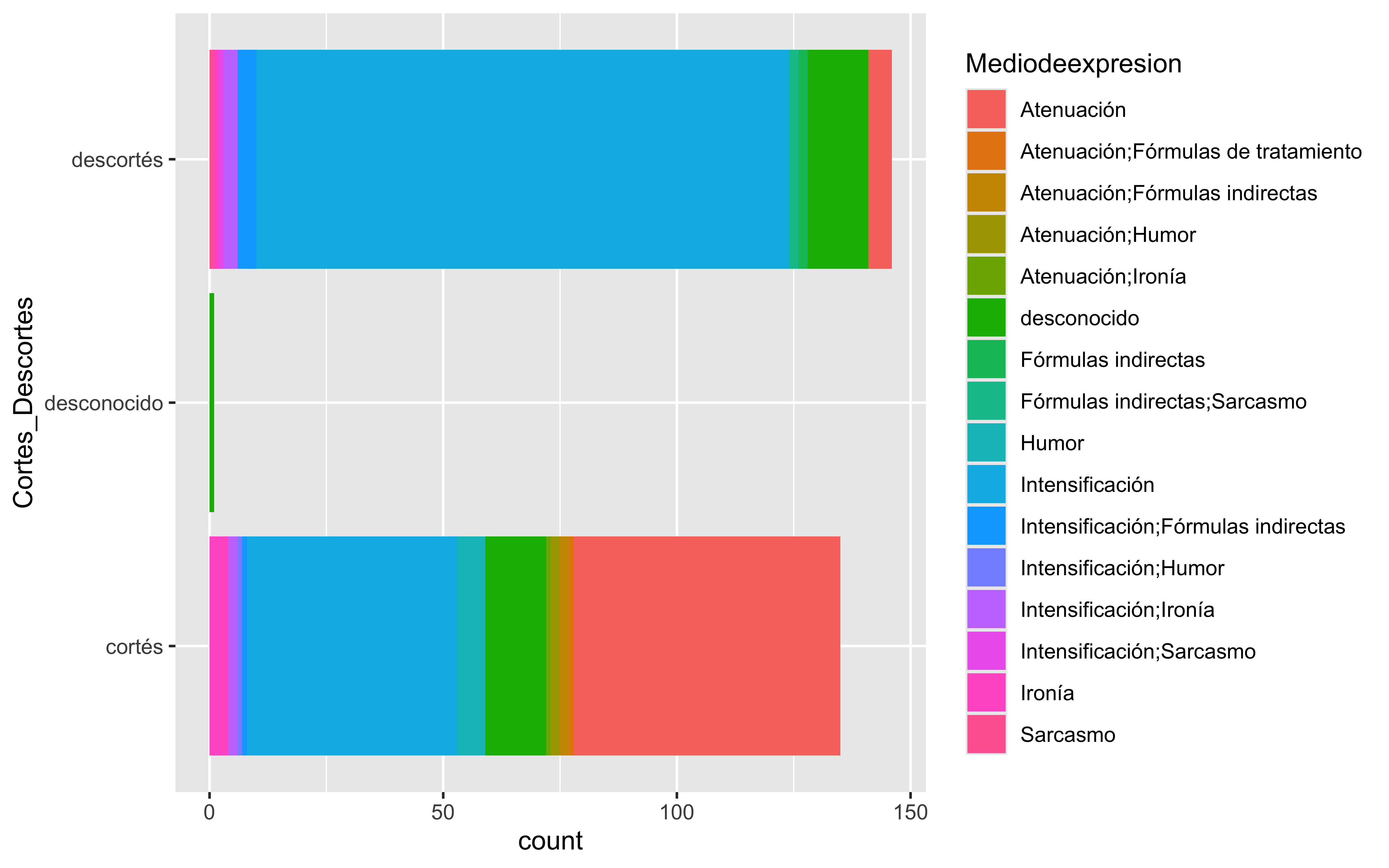
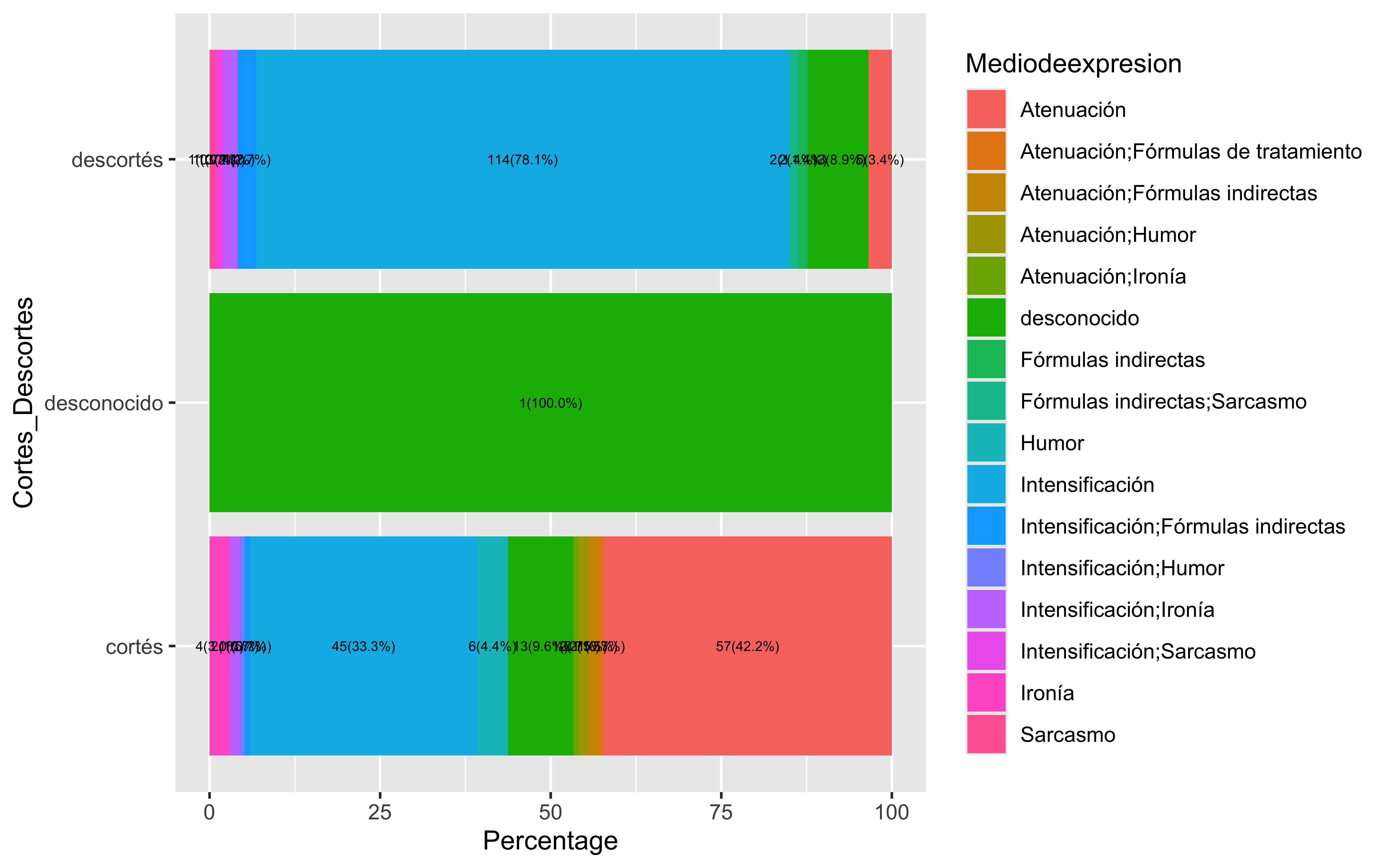
data <- fonocortesia%>%group_by(Cortes_Descortes,Mediodeexpresion)%>%summarise(Total =sum(n())) %>%mutate(Percentage = Total /sum(Total) *100)ggplot(data, aes(x=Cortes_Descortes,y=Percentage, fill=Mediodeexpresion))+geom_bar(stat="identity") +geom_text(aes(label =paste(Total, "(", sprintf("%.1f%%", Percentage), ")", sep ="")),position =position_stack(vjust =0.5), # Center text in the middle of each bar segmentsize =2# Adjust text size ) +coord_flip()
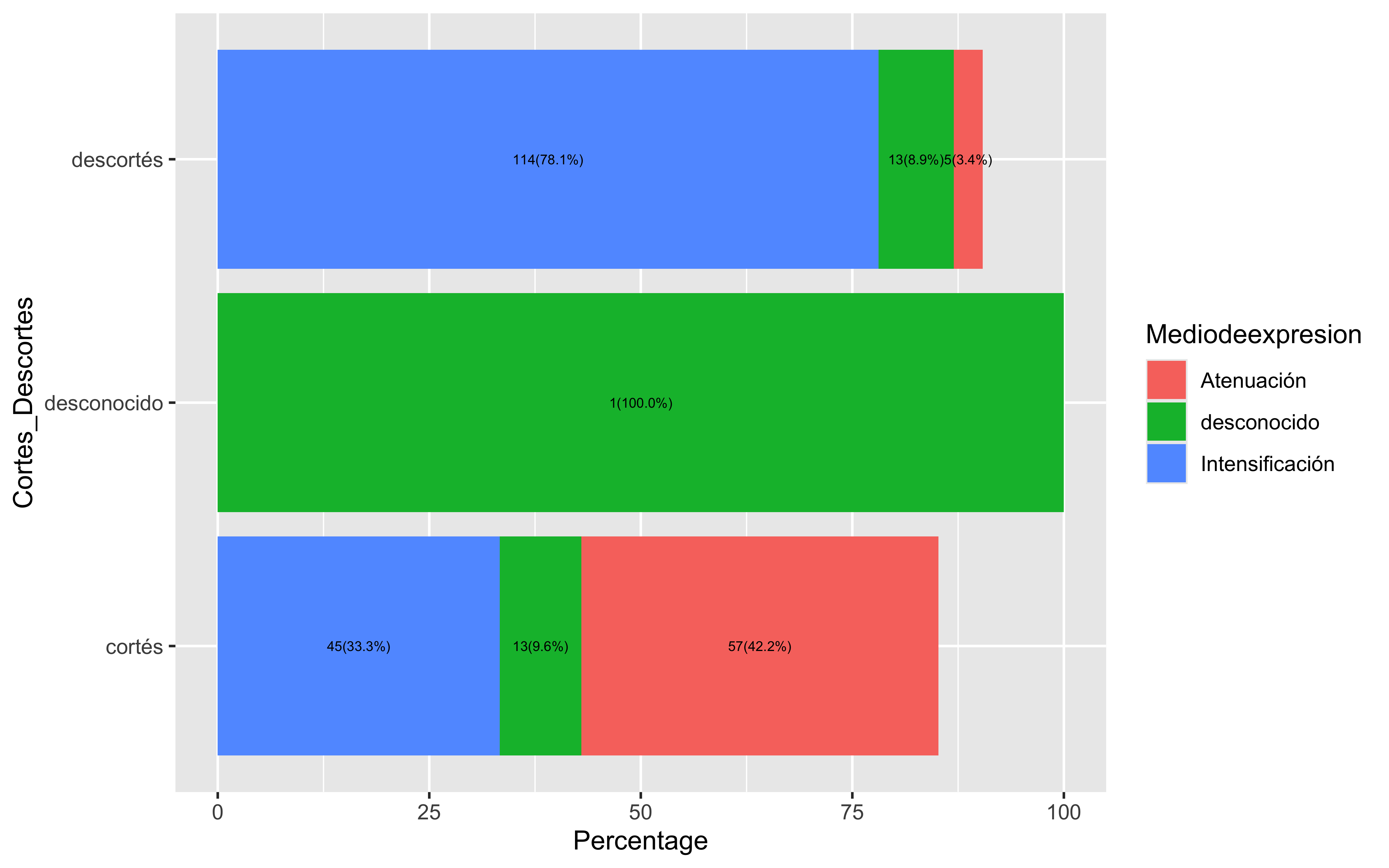
ggplot(data%>%filter(Mediodeexpresion%in%c("Atenuación","Intensificación","desconocido")), aes(x=Cortes_Descortes,y=Percentage, fill=Mediodeexpresion))+geom_bar(stat="identity") +geom_text(aes(label =paste(Total, "(", sprintf("%.1f%%", Percentage), ")", sep ="")),position =position_stack(vjust =0.5), # Center text in the middle of each bar segmentsize =2# Adjust text size ) +coord_flip()
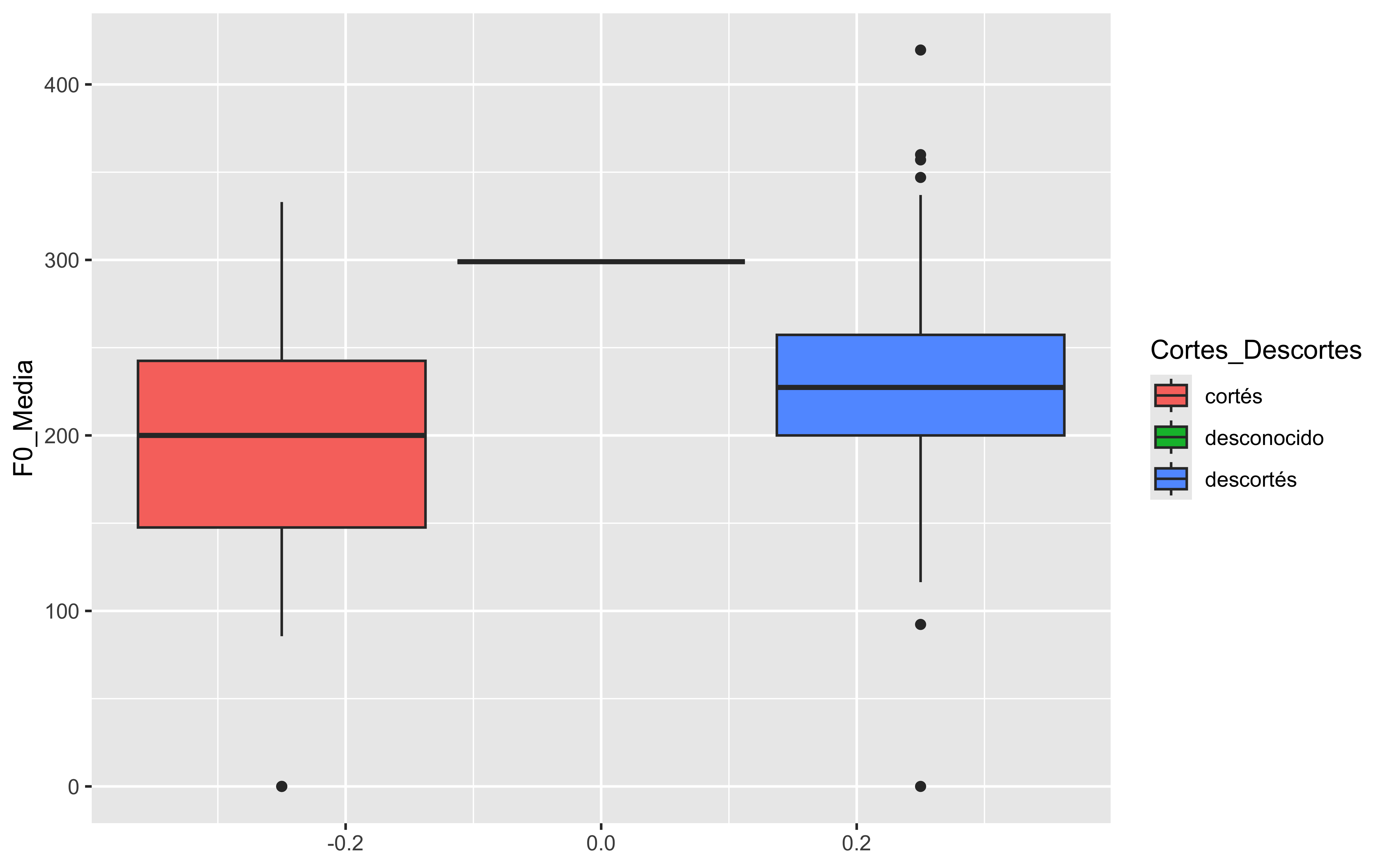
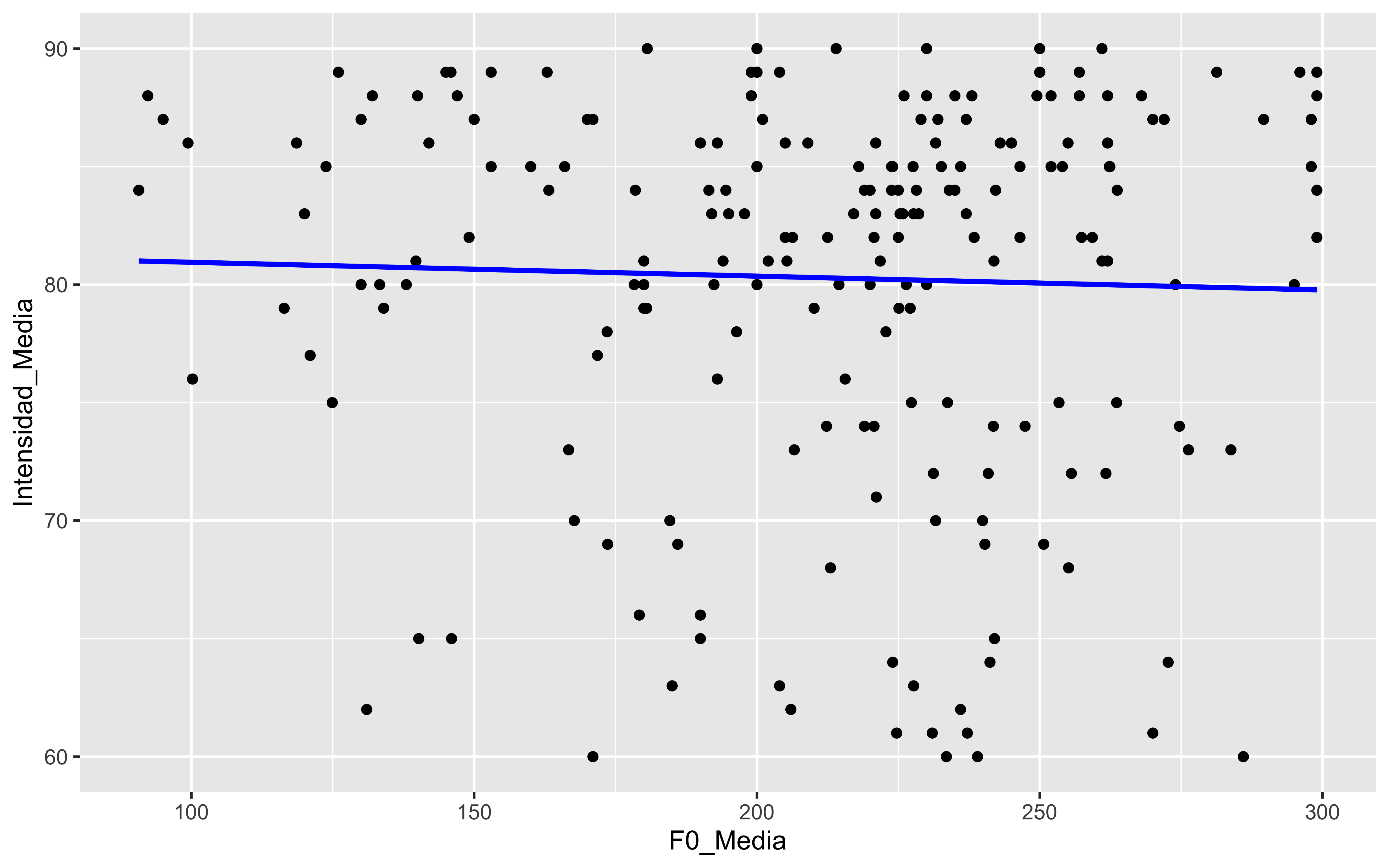
El gráfico de violín es una combinación de un diagrama de caja y un gráfico de densidad. Muestra la distribución de los datos en función de una variable categórica.
La densidad de un conjunto de datos es una estimación de la distribución de probabilidad subyacente de los datos. Los gráficos de densidad muestran la distribución de los datos en forma de una curva suave.
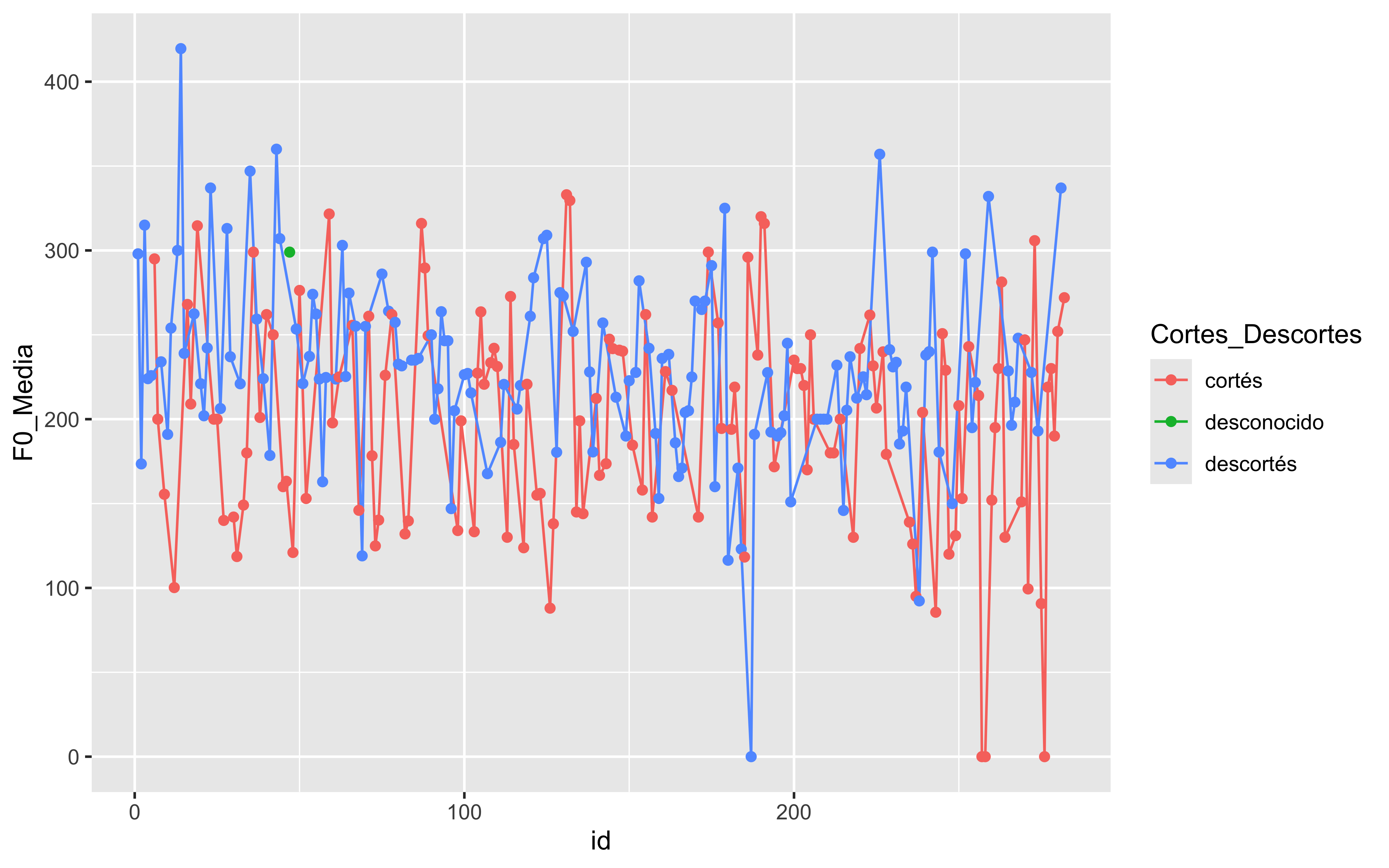
lolipop <- fonocortesia%>%group_by(Cortes_Descortes)%>%summarise(f0_mean=mean(F0_Media,na.rm = T))ggplot(lolipop, aes(x=Cortes_Descortes, y=f0_mean, fill = Cortes_Descortes, color =Cortes_Descortes)) +# Mapear 'z' al tamañogeom_point(aes(size = f0_mean), alpha =0.6) +# Añadir puntos de dispersión con transparenciageom_segment(aes(x=Cortes_Descortes, xend=Cortes_Descortes, y=0, yend=f0_mean)) +coord_flip()
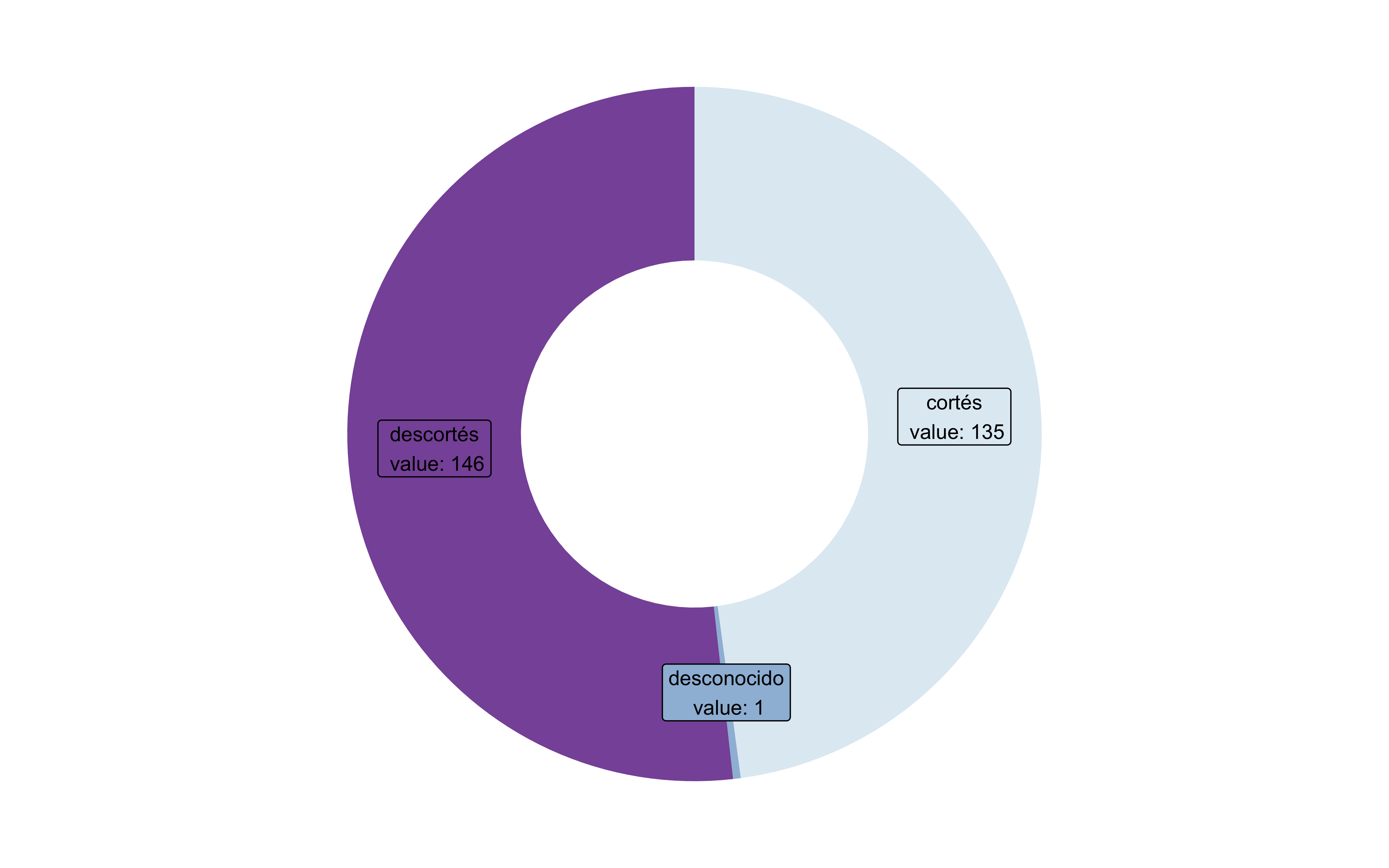
11.3.11 Gráficos de donut
data <- fonocortesia%>%group_by(Cortes_Descortes)%>%summarise(count=n())%>%na.omit()%>%rename(category=Cortes_Descortes, count=count)data$fraction <- data$count /sum(data$count)# Compute the cumulative percentages (top of each rectangle)data$ymax <-cumsum(data$fraction)# Compute the bottom of each rectangledata$ymin <-c(0, head(data$ymax, n=-1))# Compute label positiondata$labelPosition <- (data$ymax + data$ymin) /2# Compute a good labeldata$label <-paste0(data$category, "\n value: ", data$count)# Make the plotggplot(data, aes(ymax=ymax, ymin=ymin, xmax=4, xmin=3, fill=category)) +geom_rect() +geom_label( x=3.5, aes(y=labelPosition, label=label), size=3) +scale_fill_brewer(palette=3) +coord_polar(theta="y") +xlim(c(2, 4)) +theme_void() +theme(legend.position ="none")
11.3.12 Gráficos de mapa de calor
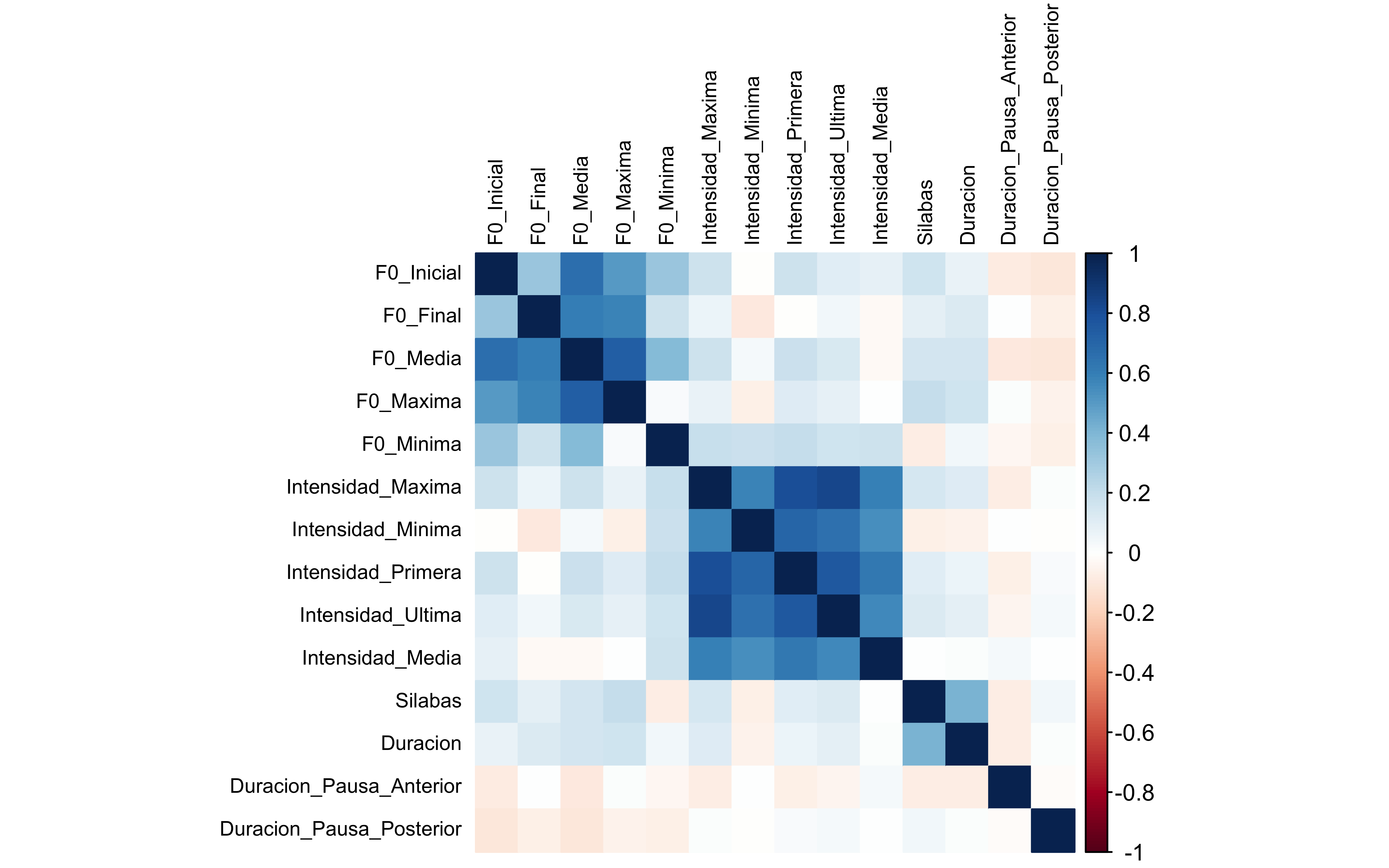
library(gplots)png(filename='heatmap.png', width=2400, height=1550, res=300)# Ajustar márgenespar(mar=c(5,4,4,2) +0.1)# Cargar datos y procesarlosp <- fonocortesia %>%group_by(Cortes_Descortes) %>%summarise_all(mean, na.rm =TRUE) %>%column_to_rownames(var="Cortes_Descortes") %>%select_if(is.numeric) %>%select(F0_Media, Duracion, Intensidad_Media)# Generar el heatmapheatmap.2(as.matrix(p), na.rm =TRUE, scale="column", cexCol =0.8, cexRow =0.8)# Cerrar el dispositivo gráficodev.off()
11.3.13 Nube de palabras
library(ggwordcloud)df_words <- fonocortesia %>%select(Cortes_Descortes,Elemento_Analizado)%>%mutate(word =str_split(Elemento_Analizado, " "),cortesia=Cortes_Descortes) %>%# Dividir el texto en palabrasunnest(word) %>%group_by(cortesia,word) %>%summarise(frecuencia =n())%>%filter(frecuencia>2) ggplot(df_words%>%filter(!word%in%c("A:","B:","C:","L:","M:","(...)")), aes(label = word, size = frecuencia,color=cortesia)) +geom_text_wordcloud(area_corr =TRUE) +scale_size_area(max_size =20) +theme_minimal()
12 Ejercicios
Importa los datos del archivo idiolectal.xlsx y explora su estructura.
Haz dos dataframes según la variable genre. Cada uno de ellos debe contener los datos solo de un género.
Crea un dataframe llamado “piquito_relocado” y ubica la variable tonemes delante de genre
Visualiza en un gráfico de líneas en el dataframe “idiolectal” la evolución de los tonemas solo en el archivo 5pangelreal.
Crea un dataframe llamado “piquito_filtrado” en el que filtre todos los datos que no sean NA en la variable tonemeMAS.
Crea un diagrama de caja de la variable dur en el dataframe “idiolectal”. ¿Sabrías crearlos por hablante en un mismo gráfico? Hay varias maneras de hacerlo.
¿Cuántos tonemas hay en el dataframe “idiolectal”? Visualízalo en una tabla y en un gráfico de barras usando la base de datos “piquito_filtrado”
Correlaciona en el dataframe “idiolectal” las variables numéricas de este estudio.
Haz una tabla de frecuencias de cada hablante en el dataframe “idiolectal” y saca la media de tonemeMAS, de dur y de body
Visualiza la información anterior en un mapa de calor.
Source Code
---title: "TÉCNICAS ESTADÍSTICAS DE VISUALIZACIÓN Y VALIDEZ POBLACIONAL CON R MEDIANTE DATOS PRAGMÁTICOS Y FÓNICOS"author: - name: Adrián Cabedo Nebot orcid: email: adrian.cabedo@uv.es affiliations: - name: Universitat de València address: Avda. Blasco Ibáñez, 32 city: Valencia postal-code: 46010execute: warning: false echo: trueformat: pdf: code-line-numbers: true fig-cap-location: bottom table-of-contents: true number-sections: true fig-dpi: 300 fig-width: 8 include-in-header: text: | \usepackage[all]{nowidow} \clubpenalty=10000 \widowpenalty=10000 \displaywidowpenalty=10000 html: mermaid: theme: forest theme: yeti fig-dpi: 300 fig-width: 8 fig-cap-location: bottom table-of-contents: true number-sections: true toc: true toc-title: "Índice" toc-expand: 1 toc-depth: 4 code-fold: false code-block-bg: true code-tools: true highlight-style: arrow code-line-numbers: true format-links: falseeditor: visual---| | ||---------------------------------|---------------------------------------|| {width="123"} | {width="243"} |Curso diseñado para el [Servei de Formació Permanent](https://www.uv.es/uvweb/centro-formacion-calidad-manuel-sanchis-guarner/es/centro-formacion-calidad-sanchis-guarner-1285909558032.html) de la Universitat de València.**Email:** [adrian.cabedo\@uv.es]{.underline}**Celebrado los días**: 20, 23, 27 y 30 de mayo de 2024**Copyright y derechos:**<pxmlns:cc="http://creativecommons.org/ns#"xmlns:dct="http://purl.org/dc/terms/">[Curso estadística 2024 para el Servei de Formació Permanent]{property="dct:title"} by [Adrián Cabedo Nebot]{property="cc:attributionName"} is licensed under <ahref='https://creativecommons.org/licenses/by/4.0/?ref=chooser-v1'target='_blank'rel='license noopener noreferrer'style='display:inline-block;'>CC BY 4.0{width="100" height="34"}</a></p># Programa del curso## ResumenEl curso ofrece una inmersión completa en el análisis y aprovechamiento de bases de datos lingüísticas, superando las limitaciones de herramientas convencionales como Excel y Google Sheets. Los participantes adquirirán una sólida comprensión de R, un lenguaje de programación esencial en análisis de datos. Además, explorarán técnicas estadísticas avanzadas para visualizar y analizar datos lingüísticos y poblacionales. Aprenderán a crear visualizaciones descriptivas impactantes utilizando GGplot2, aplicarán Mosaicplot y pruebas de chi cuadrado para investigar relaciones categóricas, identificarán patrones en datos multidimensionales mediante análisis de correspondencias y componentes, utilizarán árboles de decisiones para tomar decisiones basadas en datos y explorarán relaciones no lineales, y generarán mapas de calor para visualizar correlaciones y tendencias en datos numéricos. Este curso proporciona una base para el análisis avanzado de datos lingüísticos y poblacionales.## Objetivos específicos• Adquirir habilidades avanzadas en el manejo de bases de datos lingüísticas más allá de las hojas de cálculo tradicionales como Excel o Google Sheets.• Familiarizarse con el programa R, aprendiendo los conceptos básicos de programación y análisis de datos en este entorno.• Desarrollar la capacidad de representar datos de manera efectiva utilizando técnicas de visualización avanzadas, incluyendo barras, lolipops, diagramas de caja y líneas temporales utilizando GGplot2 en R.• Adquirir habilidades avanzadas en el análisis de datos, utilizando diversas técnicas estadísticas y de visualización, como Mosaicplot y pruebas de chi cuadrado para explorar relaciones entre variables categóricas, análisis de correspondencias múltiples y análisis de componentes para identificar patrones en datos multidimensionales, la construcción de árboles de decisiones para tomar decisiones basadas en datos y la exploración de relaciones no lineales, así como la generación de mapas de calor para visualizar patrones de correlación y tendencias en datos numéricos.## Contenidos1. Análisis y explotación de una base de datos lingüística: más allá de Excel/Goole Sheets2. Introducción básica al manejo del programa R3. Técnicas estadísticas de visualización y contraste poblacional i) Visualización descriptiva (barras, lolipops, diagramas de caja, líneas temporales…) con GGplot2. ii) Mosaicplot y chi cuadrado Análisis múltiple de correspondencias / Análisis de componentes iii) Árboles de decisiones iv) Mapas de calor## Conocimientos previosSe recomienda a las personas interesadas en realizar el curso que tengan un conocimiento básico de programas de hojas de datos como, por ejemplo, Excel o, al menos, que conozcan su estructura general. También es recomendable que hayan realizado investigaciones previas con datos.## Requisitos técnicosSe recomienda a quien acuda al curso que tenga previamente instalado R (<https://cran.rediris.es/>) y RStudio (<https://posit.co/download/rstudio-desktop>) en su propio ordenador portátil, independientemente de que la realización del curso pueda impartirse en algún aula con ordenadores. Ambos son programas gratuitos y pueden instalarse en Linux, Windows y Mac.## Sobre los datos de este cursoEn este curso, utilizaremos datos lingüísticos, específicamente datos pragmáticos y fónicos, como ejemplos prácticos para aprender a trabajar con R y desarrollar habilidades estadísticas avanzadas. Sin embargo, es importante comprender que el enfoque principal de este curso va más allá de los datos lingüísticos en sí. Las técnicas y pruebas que aprenderán aquí son universales y se pueden aplicar a una amplia gama de datos en diferentes campos y disciplinas. Nuestro objetivo es capacitar a quienes asistan para que se conviertan en analistas de datos competentes y versátiles que puedan abordar y resolver problemas utilizando R y técnicas estadísticas, independientemente del tipo de datos con el que trabajen en el futuro.## EvaluaciónLos contenidos se evaluarán a través de la asistencia y las prácticas realizadas en el aula, así como de la realización de un breve cuestionario online a la finalización del curso. En este cuestionario se preguntará sobre los ejemplos prácticos expuestos en clase.## Bibliografía recomendada::: {.callout-tip title="Referencias recomendas"}- Este mismo documento.- Cabedo Nebot, A. (2021). *Fundamentos de estadística con R para lingüistas*. Tirant Lo Blanch.- Gries, S. Th. (2021). *Statistics for Linguistics with R: A Practical Introduction*. De Gruyter. <https://doi.org/10.1515/9783110718256>- Levshina, N. (2015). *How to do Linguistics with R: Data exploration and statistical analysis*. John Benjamins Publishing Company.- Moore, D. S., & McCabe, G. P. (1999). *Introduction to the practice of statistics*. W.H. Freeman.- Navarro, D. (2015). *Learning statistics with R: A tutorial for psychology students and other beginners. (*. University of Adelaide. <https://learningstatisticswithr.com/>:::## ¿Dónde voy cuando me atasco?::: {.callout-tip title="Fuentes de ampliación y ayuda"}<https://chatgpt.com/?oai-dm=1><https://stackoverflow.com/><https://forum.posit.co/>:::# Y hubo un principio...## ¿Qué hago en mi investigación?{width="607"}Images created by an AI from OpenAI## ¿Por qué analizar datos?{width="607"}Image created by an AI from OpenAI\newpage## ¿Cómo siente un lingüista la estadística?| | | ||------------------------|------------------------|------------------------||  |  |  |Images created by an AI from OpenAI# Sobre R::: {.callout-caution icon="false" title="Funcionalidades de R"}- **Análisis Estadístico**: Desde análisis descriptivos básicos hasta modelos estadísticos avanzados y pruebas de hipótesis.- **Visualización de Datos**: Creación de gráficos y mapas detallados para explorar y presentar datos de manera efectiva.- **Manipulación de Datos**: Transformación, limpieza y preparación de datos para análisis mediante paquetes como dplyr y tidyr.- **Modelado Predictivo**: Desarrollo de modelos de machine learning, incluyendo regresión, clasificación y clustering.- **Generación de Informes**: Automatización de informes y creación de documentos reproducibles con R Markdown.- **Interfaz de Programación**: Desarrollo de aplicaciones interactivas y dashboards usando Shiny para presentaciones dinámicas de datos.:::# Sobre R (II)Vale, pero, ¿qué hace realmente R?```{r}library(tidyverse)library(gridExtra)frase <-unlist(strsplit("la noche en la que suplico que no salga el sol", " "))# Crear el data framedatos <-data.frame(palabra = frase, tiempo =seq(0, length(frase) -1), pitch =runif(length(frase), min=80, max=90), intensidad =runif(length(frase), min=70, max=85) )# Create the plot with labelsplot <-ggplot(datos) +geom_point(aes(x = tiempo, y = pitch, color ="Pitch")) +geom_smooth(aes(x = tiempo, y = pitch, color ="Pitch")) +geom_text(aes(x = tiempo, y = pitch, label = palabra), vjust =-1, hjust =0.5, size =3.5, check_overlap =TRUE) +geom_point(aes(x = tiempo, y = intensidad, color ="Intensidad")) +geom_smooth(aes(x = tiempo, y = intensidad, color ="Intensidad")) +labs(color ="Variable") +# Add text labels above pointstheme_minimal() plot```Figura extraída con GGplot2. Curva melódica y de intensidad del enunciado *la noche en la que no salga el sol*# ¿Qué más puedo hacer con R?::: {.callout-tip title="Más funcionalidades"}- Escribir documentos científicos mediante Rmarkdown o Quarto (este mismo documento ha sido escrito en R).- Exportar tus documentos a varios formatos: PDF, Word o Powerpoint.- Modificación de las plantillas. Ejemplo: revista [*Normas*](https://ojs.uv.es/index.php/normas/) de la UV.- Programar scripts que realicen funciones de manera automática. Por ejemplo, abre todos los archivos de una carpeta e impórtalos.- Crear aplicaciones web para consultar datos. Ej.: [Oralstats](https://acabedo.quarto.pub/oralstats/).:::# ¿Desde dónde instalo R y RStudio?- [R](https://cran.rediris.es/)- [RStudio](https://posit.co/download/rstudio-desktop)- Puedes usar también una versión gratuita online (con limitaciones de uso, pero suficiente para este curso y para un uso puntual): <https://posit.cloud/># ¿Por qué RStudio?::: {.callout-note title="Justificación de R"}- RStudio es un entorno de desarrollo integrado (IDE) para R.- RStudio simplifica la programación en R y mejora la productividad del usuario.- RStudio es gratuito y de código abierto.- RStudio es multiplataforma (Windows, Mac y Linux).:::# Uso de Excel o Google Sheets::: {.callout-note title="Uso de Excel"}- Formato tabular. Filas y columnas.- Organización de datos.- Tablas dinámicas para estadística básica.- Limitaciones: no permite realizar análisis estadísticos avanzados.:::## Bases de datos<https://github.com/acabedo/abralin_1/blob/main/idiolectal.xlsx><https://github.com/acabedo/databases/blob/main/r-libro/fonocortesia.xlsx>## Ejemplo de uso: Fonocortesía<https://lookerstudio.google.com/reporting/57f127e6-8e3b-4d63-8fc7-7e0226431e9c/page/9OMAB?s=iJDWulQ3Ees><https://adrin-cabedo.shinyapps.io/oralstats_v_1_3/>## Métodos de exploración avanzada en Excel o Google Sheets::: {.callout-note title="Sobre tablas dinámicas"}*Tablas dinámicas*: "Una tabla dinámica es una herramienta avanzada para calcular, resumir y analizar datos que le permite ver comparaciones, patrones y tendencias en ellos. Las tablas dinámicas funcionan de forma un poco distinta dependiendo de la plataforma que use para ejecutar Excel." (extraído de: <https://support.microsoft.com/es-es/office/crear-una-tabla-din%C3%A1mica-para-analizar-datos-de-una-hoja-de-c%C3%A1lculo-a9a84538-bfe9-40a9-a8e9-f99134456576>):::## EjercicioExplora la base de datos *Idiolectal* en Excel o Google Sheets.## Definir la construcción de la base de datos (estructura)```{mermaid}flowchart LR A[Investigación] --> B(Base de datos) B --> C{Variables} C --> D[elemento de análisis] C --> E[F0 media] C --> F[Intensidad media] C --> G[Cortesía] C --> H[...]```Figura. Proceso de construcción de la base de datos.# Uso general de R## Instalar librerías```{r}#| eval: falseinstall.packages("tidyverse")install.packages("FactoMineR")install.packages("factoextra")install.packages("partykit")install.packages("randomForest")install.packages("DataExplorer")install.packages("heatmap.2")install.packages("corrplot")install.packages("ggwordcloud")```## Cargar librerías```{r}library(tidyverse)library(corrplot)library(FactoMineR)library(factoextra)library(partykit)library(randomForest)library(DataExplorer)library(gplots)library(ggwordcloud)```## Importar datos```{r}library(readxl)fonocortesia <-read_xlsx("databases/corpus.xlsx")```## Conoce la estructura de tus datos: str o summary```{r}str(fonocortesia)``````{r}summary(fonocortesia)```## Citar R```{r}citation()citation("tidyverse")```## Data framesUn data frame es una estructura de datos en R que se utiliza para almacenar datos en forma tabular. Es similar a una matriz, pero cada columna puede contener un tipo de datos diferente.```{r}data.frame(cortesia =c("cortés", "descortés", "cortés"),f0_media =c(145, 187, 135),sexo =c("Hombre", "Mujer", "Hombre"))```::: {.callout-note title="Visualizar data frames"}Los data frames se pueden visualizar en RStudio en la pestaña "Environment" o escribiendo el nombre del data frame en la consola. Para mejorar la visualización, puedes usar la función `View()`.:::# Tareas de limpieza y manipulación de datos1. **Revisión y corrección de valores faltantes**: - Identificar y manejar los valores no disponicles (**`NA`** en R). - Decidir si imputar los valores faltantes con la media, mediana, moda, o algún otro método, o eliminar las filas/columnas con valores faltantes.2. **Detección y manejo de valores atípicos**: - Identificar valores atípicos o outliers que pueden distorsionar el análisis. - Decidir si eliminar, transformar o tratar de otra manera estos valores.3. **Estandarización y normalización de datos**: - Estandarizar unidades de medida para asegurarse de que sean consistentes. - Normalizar o estandarizar variables si es necesario para ciertos tipos de análisis.4. **Conversión de tipos de datos**: - Asegurarse de que los datos estén en los tipos adecuados (por ejemplo, convertir variables categóricas a factores en R).5. **Revisión de la coherencia de los datos**: - Verificar que no haya inconsistencias en los datos (por ejemplo, un valor de edad negativo). - Asegurar que los valores categóricos estén correctamente codificados y no haya variaciones como "Hombre" y "hombre".6. **Eliminación de duplicados**: - Identificar y eliminar registros duplicados que puedan afectar el análisis.7. **Corrección de errores tipográficos y de entrada de datos**: - Revisar y corregir errores tipográficos o de entrada manual en los datos.8. **Creación de variables derivadas**: - Crear nuevas variables que puedan ser útiles para el análisis, como agregar una variable que represente la diferencia entre dos fechas (edad, duración, etc.).9. **Filtrado de datos irrelevantes**: - Eliminar columnas o filas que no sean relevantes para el análisis específico.## ¿Qué es Tidyverse?{width="118"} <https://www.tidyverse.org/>::: callout-noteColección de paquetes de R diseñados para la ciencia de datos.- **dplyr**: manipulación de datos.- **ggplot2**: visualización de datos.- **tidyr**: limpieza de datos.- **readr**: importación de datos.- ...:::## Filtrar datos1. Ver los datos (table)2. Filtrar datos (filter)::: {.callout-important title="Notas importantes"}- El operador `%>%` se utiliza para encadenar funciones en R. Se lee de izquierda a derecha, lo que facilita la lectura del código.- El operador `==` se utiliza para comparar si dos valores son iguales.- EL operador `!=` se utiliza para comparar si dos valores son diferentes.- El operador `<-` se utiliza para crear un nuevo objeto (variable, dataframe...) en R.:::```{r}table(fonocortesia$Cortes_Descortes)fonocortesia%>%filter(Cortes_Descortes=="desconocido")table(fonocortesia$Cortes_Descortes)fonocortesia_filt <- fonocortesia%>%filter(Cortes_Descortes!="desconocido")```## Seleccionar columnas: select```{r}fonocortesia_sel <- fonocortesia%>%select(Cortes_Descortes, F0_Media, Intensidad_Media)```## Ordenar datos: arrange```{r}fonocortesia_ord <- fonocortesia%>%arrange(F0_Media)```## Reordernar columnas:: relocate```{r}fonocortesia_reord2 <- fonocortesia%>%relocate(Cortes_Descortes, .after = Intensidad_Media)```## Crear nuevas columnas: mutateEjemplo: convertir Hz a Semitono```{r}fonocortesia_nueva <- fonocortesia%>%mutate(F0_media_norm =12*log2(F0_Media/1))```## Agrupar datos: group_by```{r}fonocortesia_agrup <- fonocortesia%>%group_by(Cortes_Descortes)%>%mutate(F0_media_mean =mean(F0_Media,na.rm = T), Intensidad_media_mean =mean(Intensidad_Media,na.rm = T))```## Resumir datos: summarise```{r}fonocortesia_resumen <- fonocortesia%>%group_by(Cortes_Descortes)%>%summarise(F0_media_mean =mean(F0_Media,na.rm = T), Intensidad_media_mean =mean(Intensidad_Media,na.rm = T))```# Visualización de datosEn esta sección, aprenderemos a visualizar datos utilizando el paquete *ggplot2* en R. GGplot2 es una librería de visualización de datos en R que permite crear gráficos de alta calidad de manera sencilla y flexible.## ¿Por qué visualizar datos?Visualizar datos es una parte fundamental del análisis de datos. Las visualizaciones permiten explorar los datos, identificar patrones y tendencias, comunicar resultados y conclusiones, y tomar decisiones adecuadas y coherentes. Las visualizaciones efectivas pueden ayudar a resumir y presentar datos de manera clara y concisa; esto facilita la interpretación y comprensión de los datos.{width="467"}Images created by an AI from OpenAI## ¿Qué es ggplot2?GGplot2 es una librería de visualización de datos en R que permite crear gráficos de alta calidad de manera sencilla y flexible. GGplot2 se basa en la gramática de gráficos, un enfoque que descompone los gráficos en componentes básicos (datos, estética, geometría, estadísticas y facetas) y permite construir gráficos complejos combinando estos componentes de manera intuitiva.## Tipos de gráficosLos gráficos más comunes que se pueden crear con ggplot2 incluyen: gráfico de barras, gráfico de líneas, gráfico de dispersión, gráfico de violín, gráfico de áreas, gráfico de burbujas, gráfico de donut, gráfico de lolipop, gráfico de mapa de calor, gráfico de densidad, gráfico de correlaciones, gráfico de árbol...### Gráficos de barras#### Barras 1```{r}ggplot(fonocortesia, aes(x=Cortes_Descortes)) +geom_bar(stat="count")```#### Barras 2```{r}fonocortesia%>%ggplot(aes(x=Cortes_Descortes, fill=Mediodeexpresion)) +geom_bar(stat="count")```#### Barras 3```{r}fonocortesia%>%ggplot(aes(x=Cortes_Descortes, fill=Tonema)) +scale_x_discrete(guide =guide_axis(n.dodge=3))+geom_bar(stat="count") +facet_wrap(~Tonema)```#### Barras 4```{r}fonocortesia%>%ggplot(aes(x=Cortes_Descortes, fill=Mediodeexpresion)) +geom_bar(stat="count") +coord_flip()```#### Barras 5```{r}data <- fonocortesia%>%group_by(Cortes_Descortes,Mediodeexpresion)%>%summarise(Total =sum(n())) %>%mutate(Percentage = Total /sum(Total) *100)ggplot(data, aes(x=Cortes_Descortes,y=Percentage, fill=Mediodeexpresion))+geom_bar(stat="identity") +geom_text(aes(label =paste(Total, "(", sprintf("%.1f%%", Percentage), ")", sep ="")),position =position_stack(vjust =0.5), # Center text in the middle of each bar segmentsize =2# Adjust text size ) +coord_flip() ``````{r}ggplot(data%>%filter(Mediodeexpresion%in%c("Atenuación","Intensificación","desconocido")), aes(x=Cortes_Descortes,y=Percentage, fill=Mediodeexpresion))+geom_bar(stat="identity") +geom_text(aes(label =paste(Total, "(", sprintf("%.1f%%", Percentage), ")", sep ="")),position =position_stack(vjust =0.5), # Center text in the middle of each bar segmentsize =2# Adjust text size ) +coord_flip() ```### Diagramas de caja```{r}ggplot(fonocortesia, aes(y=F0_Media,fill=Cortes_Descortes)) +geom_boxplot()```### Gráfico de correlaciones```{r}library(corrplot)datosnum <- fonocortesia%>%select_if(is.numeric)correlaciones <-cor(datosnum,use ="complete.obs")corrplot(correlaciones, method ="color",tl.col ="black",tl.cex =0.7)```### Gráficos de líneas```{r}ggplot(fonocortesia%>%mutate(id=row_number()), aes(x=id,y=F0_Media,fill=Cortes_Descortes, color = Cortes_Descortes)) +geom_line() +geom_point()```### Gráficos de dispersión```{r}ggplot(fonocortesia%>%filter(between(Intensidad_Media,60,90), F0_Media<300), aes(x=F0_Media, y=Intensidad_Media)) +geom_point() +geom_smooth(method ="lm", se =FALSE, color ="blue")```### Gráficos de burbujas```{r}ggplot(fonocortesia, aes(x=Duracion, y=Intensidad_Media, size=F0_Media, fill = Cortes_Descortes, color=Cortes_Descortes)) +geom_point()```### Gráficos de áreas```{r}ggplot(fonocortesia%>%mutate(id=row_number())%>%filter(Cortes_Descortes!="desconocido"), aes(x=id, y=F0_Media, fill=Cortes_Descortes)) +geom_area() +facet_wrap(~Cortes_Descortes)```### Gráficos de violínEl gráfico de violín es una combinación de un diagrama de caja y un gráfico de densidad. Muestra la distribución de los datos en función de una variable categórica.```{r}ggplot(fonocortesia, aes(x=Cortes_Descortes, y=F0_Media, color=Cortes_Descortes, fill=Cortes_Descortes)) +geom_violin() +coord_flip()```### Gráficos de densidadLa densidad de un conjunto de datos es una estimación de la distribución de probabilidad subyacente de los datos. Los gráficos de densidad muestran la distribución de los datos en forma de una curva suave.```{r}ggplot(fonocortesia, aes(x=F0_Media)) +geom_density()```### Gráficos de lolipop```{r}lolipop <- fonocortesia%>%group_by(Cortes_Descortes)%>%summarise(f0_mean=mean(F0_Media,na.rm = T))ggplot(lolipop, aes(x=Cortes_Descortes, y=f0_mean, fill = Cortes_Descortes, color =Cortes_Descortes)) +# Mapear 'z' al tamañogeom_point(aes(size = f0_mean), alpha =0.6) +# Añadir puntos de dispersión con transparenciageom_segment(aes(x=Cortes_Descortes, xend=Cortes_Descortes, y=0, yend=f0_mean)) +coord_flip()```### Gráficos de donut```{r}data <- fonocortesia%>%group_by(Cortes_Descortes)%>%summarise(count=n())%>%na.omit()%>%rename(category=Cortes_Descortes, count=count)data$fraction <- data$count /sum(data$count)# Compute the cumulative percentages (top of each rectangle)data$ymax <-cumsum(data$fraction)# Compute the bottom of each rectangledata$ymin <-c(0, head(data$ymax, n=-1))# Compute label positiondata$labelPosition <- (data$ymax + data$ymin) /2# Compute a good labeldata$label <-paste0(data$category, "\n value: ", data$count)# Make the plotggplot(data, aes(ymax=ymax, ymin=ymin, xmax=4, xmin=3, fill=category)) +geom_rect() +geom_label( x=3.5, aes(y=labelPosition, label=label), size=3) +scale_fill_brewer(palette=3) +coord_polar(theta="y") +xlim(c(2, 4)) +theme_void() +theme(legend.position ="none")```### Gráficos de mapa de calor```{r}#| fig.width: 12#| eval: falselibrary(gplots)png(filename='heatmap.png', width=2400, height=1550, res=300)# Ajustar márgenespar(mar=c(5,4,4,2) +0.1)# Cargar datos y procesarlosp <- fonocortesia %>%group_by(Cortes_Descortes) %>%summarise_all(mean, na.rm =TRUE) %>%column_to_rownames(var="Cortes_Descortes") %>%select_if(is.numeric) %>%select(F0_Media, Duracion, Intensidad_Media)# Generar el heatmapheatmap.2(as.matrix(p), na.rm =TRUE, scale="column", cexCol =0.8, cexRow =0.8)# Cerrar el dispositivo gráficodev.off()```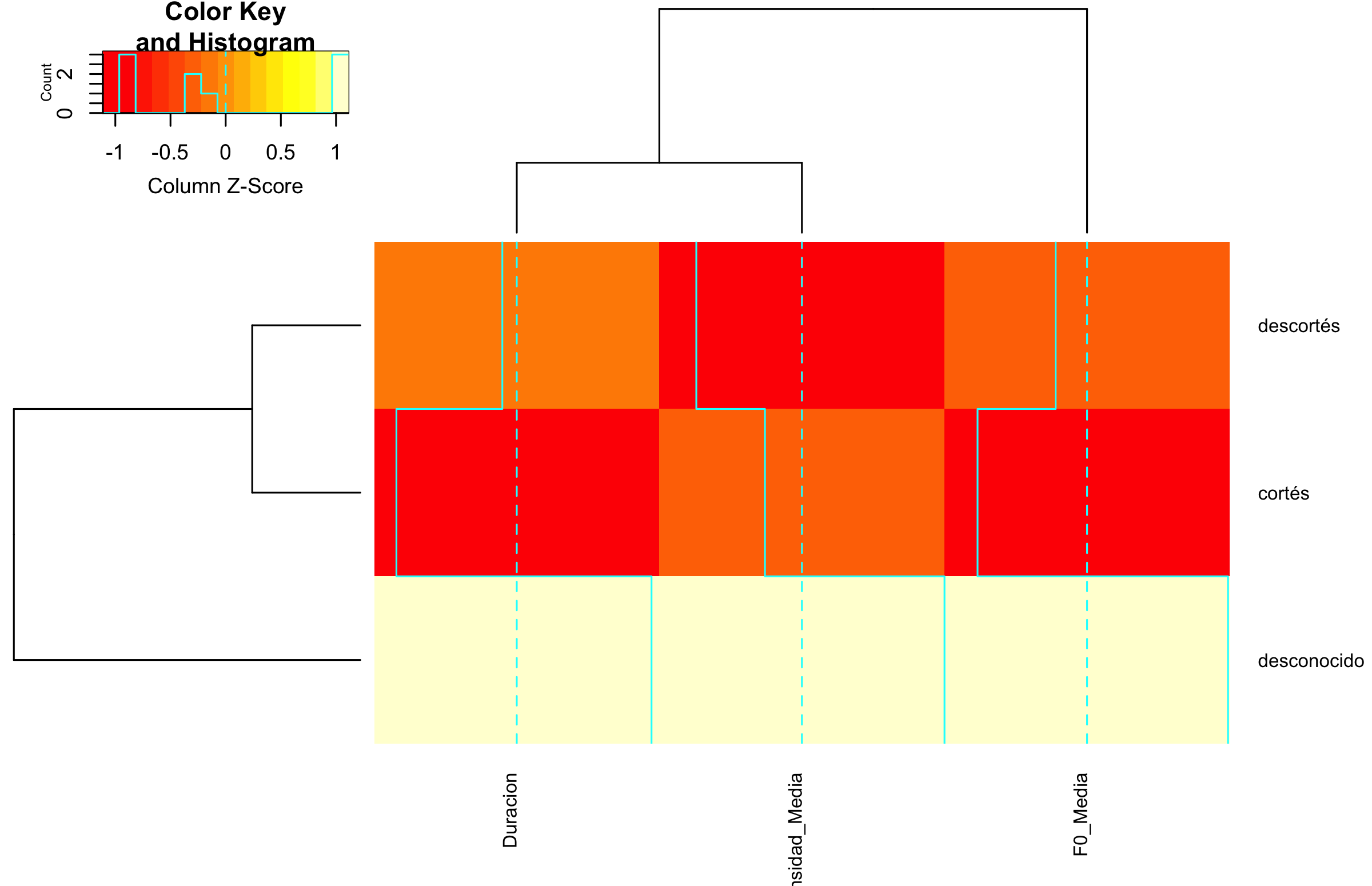### Nube de palabras```{r}library(ggwordcloud)df_words <- fonocortesia %>%select(Cortes_Descortes,Elemento_Analizado)%>%mutate(word =str_split(Elemento_Analizado, " "),cortesia=Cortes_Descortes) %>%# Dividir el texto en palabrasunnest(word) %>%group_by(cortesia,word) %>%summarise(frecuencia =n())%>%filter(frecuencia>2) ggplot(df_words%>%filter(!word%in%c("A:","B:","C:","L:","M:","(...)")), aes(label = word, size = frecuencia,color=cortesia)) +geom_text_wordcloud(area_corr =TRUE) +scale_size_area(max_size =20) +theme_minimal()```# Ejercicios1. Importa los datos del archivo **`idiolectal.xlsx`** y explora su estructura.2. Haz dos dataframes según la variable genre. Cada uno de ellos debe contener los datos solo de un género.3. Crea un dataframe llamado "piquito_relocado" y ubica la variable *tonemes* delante de *genre*4. Visualiza en un gráfico de líneas en el dataframe "idiolectal" la evolución de los tonemas solo en el archivo *5pangelreal*.5. Crea un dataframe llamado "piquito_filtrado" en el que filtre todos los datos que no sean NA en la variable *tonemeMAS*.6. Crea un diagrama de caja de la variable *dur* en el dataframe "idiolectal". ¿Sabrías crearlos por hablante en un mismo gráfico? Hay varias maneras de hacerlo.7. ¿Cuántos tonemas hay en el dataframe "idiolectal"? Visualízalo en una tabla y en un gráfico de barras usando la base de datos "piquito_filtrado"8. Correlaciona en el dataframe "idiolectal" las variables numéricas de este estudio.9. Haz una tabla de frecuencias de cada hablante en el dataframe "idiolectal" y saca la media de *tonemeMAS*, de *dur* y de *body*10. Visualiza la información anterior en un mapa de calor.