

{kind=link}

ANÁLISIS ESTADÍSTICO DE DATOS LINGÜÍSTICOS: ¿POR DÓNDE EMPEZAR?
Seminario diseñado para la Asociación de Jóvenes Lingüistas (AJL)
Email: adrian.cabedo@uv.es
Celebrado: 12 de junio de 2024
Copyright y derechos:
ANÁLISIS ESTADÍSTICO DE DATOS LINGÜÍSTICOS: ¿POR DÓNDE EMPEZAR?parala Asociación de Jóvenes Lingüistas (AJL) by Adrián Cabedo Nebot is licensed under CC BY 4.0 ![]()
1 ¿Quién era yo en 2006?

Images created by an AI from OpenAI
- Estudiante de Filología Hispánica
- NO Interesado en datos
- NO Interesado en estadística
- NO Interesado en informática
- Me gusta leer literatura (Cortázar, Poe, Lovecraft, Muñoz Molina…) y escribir poesía.
- Me gusta la música (Queen, Alice Cooper, AC/DC…).
- Me gusta más la literatura que la lingüística.
- Tengo 25 años, me estoy haciendo mayor y necesito trabajo. Futuro: oposiciones.
2 ¿Quién soy yo en 2024?

Images created by an AI from OpenAI
- Doctor en Lengua Española (2009)
- Fui miembro de la AJL de 2006 a 2009.
- Profesor titular en la UV (desde 2019)
- Interesado en datos
- Interesado en estadística
- Interesado en informática
- Me sigue gustando leer, escribir y la música
- Tengo 17 años más y ya no soy “joven lingüista”.
- Voy a congresos y hago cosas con R.
- Escribo papers…
3 Objetivos de la charla de hoy
Objetivos
- Introducir conceptos básicos de estadística.
- Introducir nociones de recogida de datos.
- Presentar herramientas para la exploración de datos.
- Mostrar ejemplos de aplicación de la estadística en lingüística.
4 Acercamientos comunes en investigación lingüística
Fuente de la imagen: |
Fuente de la imagen: https://www.rae.es/academico/guillermo-rojo |
|
|
¿Qué decimos de estos caminos?
- Ambos acercamientos se necesitan mutuamente.
- No hay uno mejor que otro, son aproximaciones diferentes.
- Puede seguirse cada camino de manera independiente (y hacerlo muy bien, o hacerlo “menos bien”).
- El rigor científico es necesario en ambos casos.
5 ¿En qué piensa muchas veces un alumno de lingüística sobre la estadística?
Fórmula de la chi-cuadrado:
\[ \chi^2 = \sum \frac{(O_i - E_i)^2}{E_i} \] Fórmula ANOVA:
\[ F = \frac{\text{MS}_{\text{between}}}{\text{MS}_{\text{within}}} \]

Images created by an AI from OpenAI
6 Reticencias ante el uso de datos
Reticencias ante el uso de datos
- Soy de letras.
- No sé de matemáticas.
- Todo lo de números es muy difícil y no entiendo nada.
- Los datos no sirven sin interpretación, es una manera de manipular al lector y hacer creer que un estudio es más “científico”.
- Se puede hacer en sincronía, pero no en diacronía.
- Yo no quiero programar ni usar software especializado. No se me da bien.
7 ¿Qué puede ser también estadística en lingüística?

Fuente: Albelda Marco, Marta. «Variación sociolingüística de los mecanismos mitigadores: diferencias de uso en edad y sexo». Cultura, lenguaje y representación: revista de estudios culturales de la Universitat Jaume I, 2018, Vol. 19, pp. 7-29, https://raco.cat/index.php/CLR/article/view/355769.
8 ¿Qué puede ser también estadística en lingüística diacrónica?

Fuente: de Toledo y Huerta, Á. S. O. (2016). Enseñanzas del cambio fracasado: Trayectoria y estela de una perífrasis fugaz (infinitivo + tener). Cuadernos de Lingüística de El Colegio de México, 3(1), 119. https://doi.org/10.24201/clecm.v3i1.28
9 ¿Qué puede ser también visualización estadística en lingüística de corpus?

Imagen en la que se distribuyen enunciados corteses y descorteses según sus dimensiones fónicas. Método de visualización estadística utilizada: FAMD (análisis factorial de datos múltiples).

Imagen que crea clústeres o grupos por color (forma filogénesis)
Fuente: Cabedo Nebot A. y Hidalgo Navarro A. (2023). Caracterización fónica de la (des)cortesía en el español hablado de Valencia. Aproximación cualitativo-cuantitativa. Círculo de Lingüística Aplicada a la Comunicación, 93, 131-149. https://doi.org/10.5209/clac.82314
10 ¿Qué es la estadística?
La estadística es una disciplina que aborda la recogida, el estudio, la valoración, organización y presentación de datos.
11 Utilidad
- Superar el sesgo (a veces las cosas no son como creo que son).
- Comprobar la validez de las hipótesis. Por ejemplo, en esta sesión tengo la hipótesis de que hay más gente del centro norte de España que del sur o del este. La mayor parte de vosotros tenéis una media de 25 años, sois todos guapísimos o muy inteligentes…
12 Por dónde empezar (bibliografía)
Uso de CHATGPT u otras IA (cuidado con “alucinaciones”).
Gries, S. (2016). Quantitative corpus linguistics with R: A practical introduction. En Quantitative Corpus Linguistics with R: A Practical Introduction. https://doi.org/10.4324/9781315746210
Gries, S. Th. (2021). Statistics for Linguistics with R: A Practical Introduction. De Gruyter. https://doi.org/10.1515/9783110718256
Levshina, N. (2015). How to do Linguistics with R: Data exploration and statistical analysis. John Benjamins Publishing Company.
Moore, D. S., & McCabe, G. P. (1999). Introduction to the practice of statistics. W.H. Freeman.
Navarro, D. (2015). Learning statistics with R: A tutorial for psychology students and other beginners. University of Adelaide. https://learningstatisticswithr.com/
Cabedo Nebot, A. (2021). Fundamentos de estadística con R para lingüistas. Tirant Lo Blanch.
13 Estadística descriptiva vs inferencial
Estadística descriptiva vs inferencial
- Estadística descriptiva: descripción de los datos.
- Estadística inferencial: generalización de los resultados a partir de una muestra (esta es en la que piensa la gente cuando piensa en estadística).
14 ¿Qué es un dato?
“Información sobre algo concreto que permite su conocimiento exacto o sirve para deducir las consecuencias derivadas de un hecho” (DRAE 2024)
¿Qué puede ser ese algo en concreto?

Images created by an AI from OpenAI
Definición de dato
Un dato o registro puede decirnos algo, por ejemplo, sobre un ser humano con sus características físicas o de comportamiento (orejas grandes y rojas, nariz gorda, simpático…).
Cada rasgo o característica de ese “algo” es un elemento de variación (también conocido como categoría o variante) y se aglutina en lo que llamamos variables.
15 ¿De qué puede recogerse datos en lingüística?
Tipo de elementos en lingüística sobre los que se pueden recoger datos
Un elemento lingüístico sobre el que recoger datos puede ser una palabra, una sílaba, un fonema (o alófonos correspondientes), un morfema, un sintagma, un enunciado, un párrafo, un texto, una posición discursiva, un acto de habla, un corpus, una obra, un autor, una lengua, una familia lingüística…
16 Ejemplo sobre un dato lingüístico: la palabra “perro”.

Trasladado a formato de tabla:
| Palabra | Categoría gramatical | Número | Semántica | Vocales | Consonantes | Acento |
|---|---|---|---|---|---|---|
| perro | sustantivo | singular | animal | 2 | 3 | llana |
17 ¿Qué es una variable?
Variable es una característica que puede cambiar y cuya variación es susceptible de medirse.
Tipos de variables
Variables cualitativas: no se pueden medir con una escala numérica. Por ejemplo, en lingüística, la categoría gramatical de una palabra.
Variables cuantitativas: se pueden medir. Por ejemplo, en lingüística, la frecuencia de uso de una palabra, el valor de duración de una sílaba, el valor en Hz de un formante, la longitud en palabras de un enunciado, etc.
18 ¿Qué programas puedo usar para hacer estadística?
- Excel
- SPSS
- R
- ChatGPT (alucinaciones…)
19 ¿Cómo recoger los datos?
Recogida de datos
Si menos de 500000 o 1000000 datos,
Google Sheets (viene gratis con Google Drive)
Microsoft Excel (de pago, pero más utilizado)
Precaución
Si más de 1000000 datos,
PostgreSQL (gratis)
MySQL (gratis)
SQLServer (de pago)
20 Estructura de una base de datos

Ejemplo: base de datos del proyecto Fonocortesia, desarrollado en 2013 y dirigido por el catedrático Antonio Hidalgo Navarro
21 Bases de datos (Fonocortesía)
Enlace recomendado: https://docs.google.com/spreadsheets/d/1wJ970x3PmcV9GQ7ZvjoBmdE_1NgPS7uvWp8xEIhhMA8/edit?usp=sharing
Google DataStudio: https://lookerstudio.google.com/reporting/57f127e6-8e3b-4d63-8fc7-7e0226431e9c/page/9OMAB?s=iJDWulQ3Ees
Oralstats: https://adrin-cabedo.shinyapps.io/oralstats_v_1_3/
22 Exploración inicial de datos con Excel o Google Sheets
Sobre tablas dinámicas
Una tabla dinámica es una herramienta avanzada para calcular, resumir y analizar datos que le permite ver comparaciones, patrones y tendencias en ellos. Las tablas dinámicas funcionan de forma un poco distinta dependiendo de la plataforma que use para ejecutar Excel.
(cita directa extraída de: https://support.microsoft.com/es-es/office/crear-una-tabla-din%C3%A1mica-para-analizar-datos-de-una-hoja-de-c%C3%A1lculo-a9a84538-bfe9-40a9-a8e9-f99134456576)
23 Opciones de transformación y visualización de datos
Lenguaje de programación
- R / RStudio
- Python
Soluciones de software
- Tableau
- Microsoft Power BI
- Voyant tools
- Google Data Studio
24 Correlaciones espúreas
La estadística puede llevar a conclusiones erróneas si no se tiene en cuenta el contexto y si no aplicamos un análisis crítico, procedente de nuestra experiencia y nuestro bagaje como investigadores (lecturas realizadas, experimentos previos…).
El ejemplo de más abajo lo conocí a partir de la lectura de Levshina (2015); ejemplifica perfectamente las relaciones “espúreas” entre dos elementos que parecen estar emparentados estadísticamente, pero que no lo están en realidad (a no ser que creamos en el mundo de la magia y la brujería)


25 ¿Qué es una población y una muestra?
Población y muestra
- Población es el conjunto de todos los elementos que cumplen una serie de características comunes.
- Muestra es un subconjunto de la población.

Images created by an AI from OpenAI
26 Tamaño de la muestra
Calcular tamaño de la muestra
- Error muestral: es la diferencia entre el valor real y el valor estimado.
- Nivel de confianza: es la probabilidad de que el valor real esté dentro del intervalo de confianza.
Ejemplo
- En una población de 100000 personas, si queremos un error muestral del 5% y un nivel de confianza del 95%, necesitamos una muestra de 384 personas.
Precaución
Problema: si quiero estudiar un fenómeno discursivo (la entonación de oraciones interrogativas, por ejemplo), debo asegurarme de que la muestra sea representativa de la población, que no solo es el conjunto de hablantes, sino también el propio hablante en sí.
Casuística: a veces solo tenemos la opción de recoger un único ejemplo para un hablante. Hay que intentar ampliarlos
27 Hipótesis nula y alternativa
Hipótesis nula y alternativa
La hipótesis nula (H0) es una afirmación que se supone verdadera hasta que se demuestre lo contrario.
La hipótesis alternativa (H1) es una afirmación que se supone falsa hasta que se demuestre lo contrario.
La nuestra suele ser la H1.
28 ¿Qué es un test de hipótesis?
Test de hipótesis
Un test de hipótesis es una técnica estadística que se utiliza para tomar decisiones sobre la hipótesis nula.
Ejemplos de test de hipótesis: t-test, ANOVA, chi-cuadrado, test de Wilcoxon, test de Mann-Whitney, test de Kruskal-Wallis, test de Friedman…
28.1 Ejemplos de hipótesis nula y alternativa
Ejemplos con variables numéricas
- H0: La media de la intensidad de la voz en los enunciados corteses y descorteses es la misma.
- H1: La media de la intensidad de la voz en los enunciados corteses y descorteses es distinta.
Ejemplo con variables nominales
- H0: Los enunciados corteses y descorteses (variable cortesía) no se relacionan con otros valores pragmáticos como la ironía, el humor, la intensificación o la atenuación (variable valor pragmático)
- H1: Los enunciados corteses y descorteses (variable cortesía) se relacionan con otros valores pragmáticos como la ironía, el humor, la intensificación o la atenuación (variable valor pragmático)
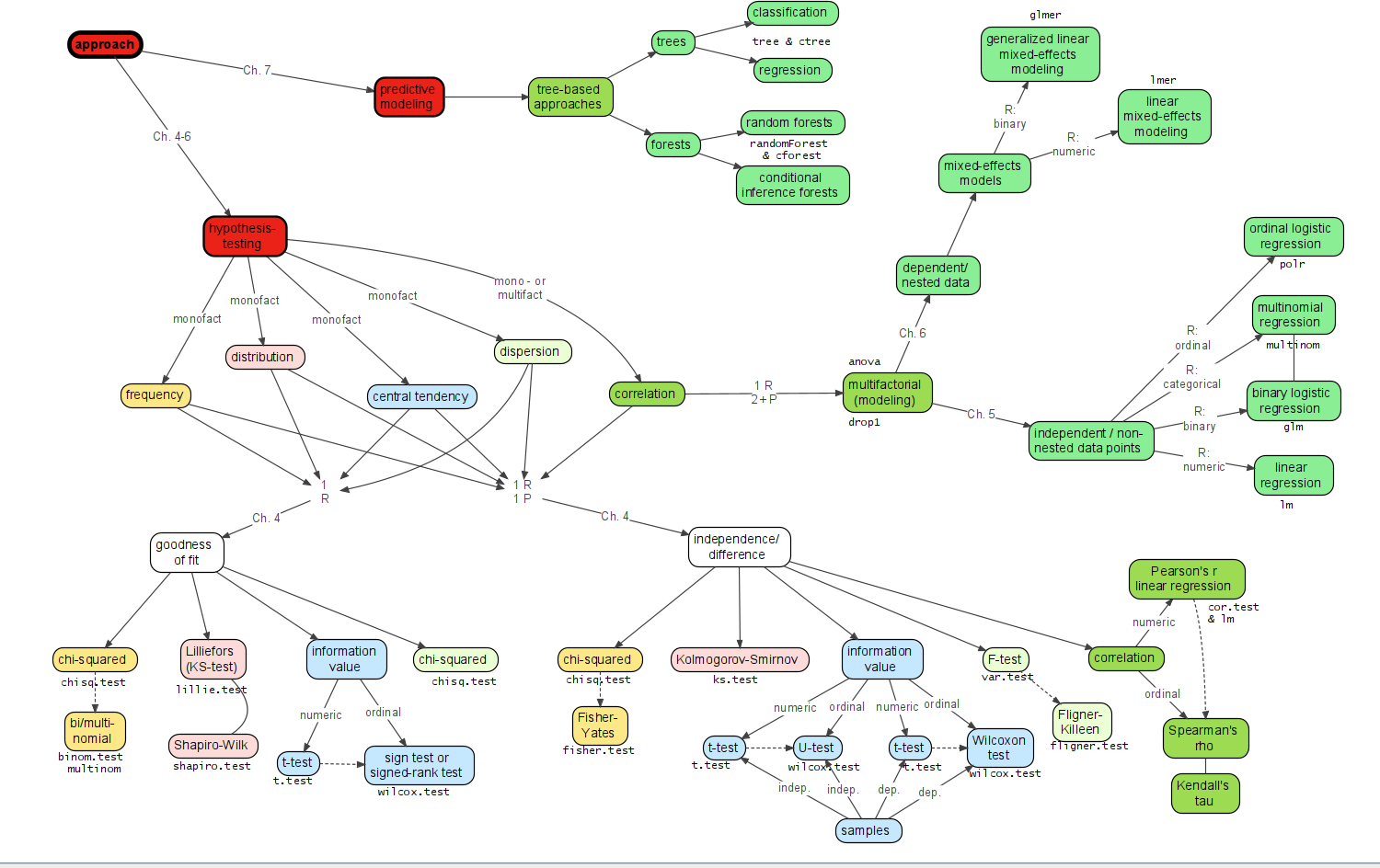
28.2 Elección de pruebas estadísticas
Hay muchas pruebas estadísticas, pero no todas son adecuadas para todos los casos. El investigador debe elegir la prueba adecuada para su estudio, así como la mejor manera para visualizar la información.
Tests sugeridos y abordados por Stefan Gries: https://www.stgries.info/research/sflwr/sflwr3_navigator.png
https://statkat.com/statistical-technique-selection/tool-for-selecting-a-statistical-technique.php
29 Errores tipo I y tipo II
Los errores tipo I y tipo II son dos tipos de errores que se pueden cometer al realizar un test de hipótesis. Por eso operamos siempre con un nivel de confianza (en síntesis, existe una probabilidad de error).
Errores tipo I y tipo II
Un error tipo I es la conclusión de que una hipótesis nula es falsa cuando en realidad es verdadera.
Un error tipo II es la conclusión de que una hipótesis nula es verdadera cuando en realidad es falsa.
30 Paradoja de Simpson
Es una paradoja en la probabilidad y estadística en la que una tendencia que aparece en varios grupos de datos desaparece o se invierte cuando se añaden nuevas informaciones o variables.
Ejemplo de la paradoja de Simpson
Ninguna disciplina está libre de esta paradoja o posibilidad de error. Nuestra disciplina tampoco lo está. Por ejemplo, en un estudio sobre la variación de la entonación en el español de Valencia, si no se tiene en cuenta el sexo del hablante o la edad, se puede llegar a conclusiones erróneas.
31 Valor p

Images created by an AI from OpenAI
El valor p es una medida de la probabilidad de que un resultado estadístico (o uno más extremo) se produzca bajo la hipótesis nula.
Regla del valor p
Menor a 0.05: 🤙 rechazamos la hipótesis nula.
Superior a 0.05: 👎 no rechazamos la hipótesis nula.
Normalmente, la H0 es la hipótesis distinta de la que queremos demostrar.
Importante
Un valor p en la prueba estadística inferior a 0.05 es lo que buscamos.
32 Distribución normal
Una distribución normal es una distribución de probabilidad que es simétrica alrededor de la media, la mediana y la moda. La curva de campana de una distribución normal es simétrica.
32.1 Regla de la normalidad
En una distribución normal, el 68% de los datos se encuentran a una desviación estándar de la media, el 95% a dos desviaciones estándar y el 99.7% a tres desviaciones estándar.

Fuente de la imagen: https://builtin.com/data-science/empirical-rule
32.2 Valor p y distribución normal
Ejemplo
Sobre una distribución normal estandarizada, el valor p es la probabilidad de que un valor igual o más extremo que el observado se produzca por azar.
Hay que tener en cuenta que el valor p no es la probabilidad de que la hipótesis nula sea cierta, sino la probabilidad de que los datos observados se produzcan si la hipótesis nula es cierta.
33 Ejemplos de valor P
33.1 ¿Es la intensidad o volumen de la voz distinta en los enunciados corteses y descorteses?
Ejemplo 1
- Enunciados corteses: 77.61 decibelios de media
- Enunciados descorteses:75.93 decibelios de media
- Valor p: 0.39
- Conclusión de investigación: los enunciados corteses y descorteses no tienen un volumen distinto.
33.2 ¿Es la F0 o tono de la voz distinta en los enunciados corteses y descorteses?
Ejemplo 2
- Enunciados corteses: 198.8 Hz de media
- Enunciados descorteses: 230.04 Hz de media
- Valor p: 0.000003
- Conclusión de investigación: los enunciados corteses y descorteses tienen valores tonales distintos (mayores en la expresión de la descortesía).

Precaución
Puede existir una variable oculta: el tono de la voz es distinto en hombres y mujeres. Si hay más hombres o mujeres en un grupo que en otro, la variable oculta puede estar influyendo en el resultado.
34 Práctica online de pruebas estadísticas
En la siguiente página, sin necesidad de instalar ningún software, pueden realizarse pruebas estadísticas básicas. Es útil si solo se requiere el dato de relación y no un gráfico.
35 Uso de un programa especializado (R)
Recomiendo utilizar el programa gratuito R junto con Rstudio para realizar estadísticas, gráficos y análisis de datos.
![]()
![]()
36 Ejemplo de gráfico simple con R

Figura extraída con GGplot2. Curva melódica y de intensidad del enunciado la noche en la que no salga el sol
37 ¿Qué más puedo hacer con R?
Más funcionalidades
Escribir documentos científicos mediante Rmarkdown o Quarto (este mismo documento ha sido escrito en R).
Exportar tus documentos a varios formatos: PDF, Word o Powerpoint.
Modificación de las plantillas. Ejemplo: la plantilla de la revista Normas de la UV se realiza con R.
Programar scripts que realicen funciones de manera automática. Por ejemplo, abre todos los archivos de una carpeta e impórtalos.
Crear aplicaciones web para consultar datos. Ej.: Oralstats.
38 ¿Desde dónde instalo R y RStudio?
- R
- RStudio
- Puedes usar también una versión gratuita online (con limitaciones de uso, pero suficiente para este curso y para un uso puntual): https://posit.cloud/